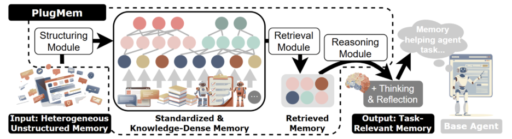
AI agents are getting smarter, but their memory systems are stuck in the past. Most agents store raw conversation logs and retrieve them when needed. This creates two problems. First, the context window fills up with low-value text. Second, the agent cannot apply lessons from one task to another. A new system called PlugMem solves both problems by converting experience into structured knowledge that works across any task.
PlugMem was developed by researchers at the University of Illinois Urbana-Champaign, Tsinghua University, and Microsoft Research. It is a task-agnostic plugin memory module that attaches to any LLM agent without custom redesign. The key insight is simple. Decision-relevant information is concentrated in abstract knowledge, not raw experience. By structuring memories into a compact knowledge graph, PlugMem lets agents recall what matters with minimal context overhead.
The Memory Problem in AI Agents
Modern AI agents handle complex tasks like web browsing, customer support, and research. These tasks require long-term memory. The agent must remember user preferences, past failures, and successful strategies. Without memory, every interaction starts from scratch.
Current approaches fall into two categories. Task-specific memory systems are designed for one purpose. They work well for that purpose but cannot transfer to other tasks. Task-agnostic systems store raw logs and retrieve them on demand. They work across tasks but suffer from low relevance and context explosion.
Consider a shopping agent. A task-specific system might remember that a user prefers organic products. But if the same user asks for travel advice, that knowledge is trapped in the shopping module. A task-agnostic system stores every conversation turn. When the user asks about travel, the agent retrieves hundreds of irrelevant shopping messages along with a few useful travel notes. The signal gets lost in the noise.
PlugMem takes a different approach. It extracts knowledge from raw interactions and organizes it into reusable units. These units are not tied to any specific task. They represent facts and skills that apply broadly.

The paper is available at https://arxiv.org/abs/2603.03296
The code is available at https://github.com/TIMAN-group/PlugMem
How PlugMem Works
PlugMem processes raw agent trajectories through three stages. Each stage transforms the data into a more useful form.
Stage one: Structuring. Raw interaction logs are messy. They contain observations, actions, and outcomes mixed together. PlugMem breaks these into standardized experience tuples. Each tuple includes the goal, state, action, reward, and next state. This format is borrowed from reinforcement learning and provides a clean foundation for knowledge extraction.
From these tuples, PlugMem extracts two types of knowledge. Propositional knowledge describes facts about the world. For example, the user is allergic to dairy products, or this website offers price sorting. Prescriptive knowledge describes how to do things. For example, to find the price range, sort low to high first, then high to low.
Stage two: Retrieval. The clothes remover ai structured knowledge is stored in a memory graph. When the agent needs information, PlugMem searches this graph for the most relevant knowledge units. The search considers the current task, the type of knowledge needed, and the relationship between different knowledge pieces.
Stage three: Reasoning. Retrieved knowledge is filtered and compressed to match the current context. This prevents our dream ai information overload and ensures the agent receives exactly what it needs. The reasoning module also handles conflicts and updates stale information.
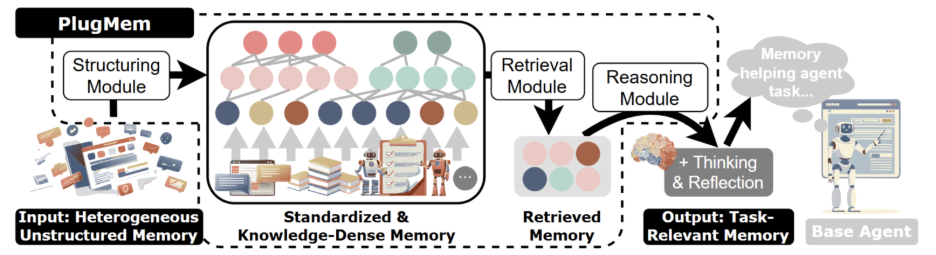
This three-stage pipeline separates memory management from task execution. Memory becomes an infrastructure layer that any agent can use. The agent does not need to know how the memory is structured. It simply asks for relevant knowledge and receives it.
Knowledge-Centric Memory Graph
PlugMem organizes memory into a graph structure inspired by cognitive science. The graph has three layers that mirror human memory systems.
Semantic memory stores facts and concepts. What things are. This includes user preferences, domain knowledge, and common sense.
Procedural memory stores skills and workflows. How to do things. This includes successful strategies, tool usage patterns, and step-by-step procedures.
Episodic memory stores raw trajectories. What happened. This serves as the foundation for extracting semantic and procedural knowledge. It also enables retrospective verification when needed.
The key difference from other graph-based systems like GraphRAG is the unit of organization. GraphRAG organizes memory around entities and text chunks. PlugMem organizes memory around knowledge units. This means retrieval returns actionable insights rather than raw text passages.
Task-Agnostic by Design
One of PlugMem’s most important features is its plug-and-play design. The module can be attached to any LLM agent without task-specific modifications. This is different from most memory systems, which require custom engineering for each new task.
The researchers tested PlugMem on three very different benchmarks. LongMemEval tests conversational question answering with 115,000 tokens of context. HotpotQA tests multi-hop knowledge retrieval across documents. WebArena tests web browsing and task completion. These tasks require different skills and memory types.
Despite the diversity, PlugMem achieved strong results on all three benchmarks without any task-specific tuning. It consistently outperformed task-agnostic baselines and even exceeded task-specific memory designs. This shows that the knowledge-centric approach is genuinely general-purpose.
As of May 2026, PlugMem has reached new state-of-the-art results with light task adaptation. It achieved 90.2 percent accuracy on LongMemEval and 79.1 F1 score on HotpotQA. The framework has also been released as installable plugins for OpenClaw and Claude Code.
Efficiency and Information Density
Memory systems are not just about accuracy. They are also about efficiency. Every token retrieved from memory costs money and slows down the agent. A system that retrieves ten thousand tokens to answer a simple question is not practical.
PlugMem addresses this through information density. The researchers developed a unified information-theoretic analysis to measure how much useful information each system delivers per token. PlugMem achieved the highest information density among all tested approaches.
This means PlugMem provides more relevant knowledge with less context overhead. The agent can make better decisions while consuming fewer resources. For production deployments, this translates to lower costs and faster response times.
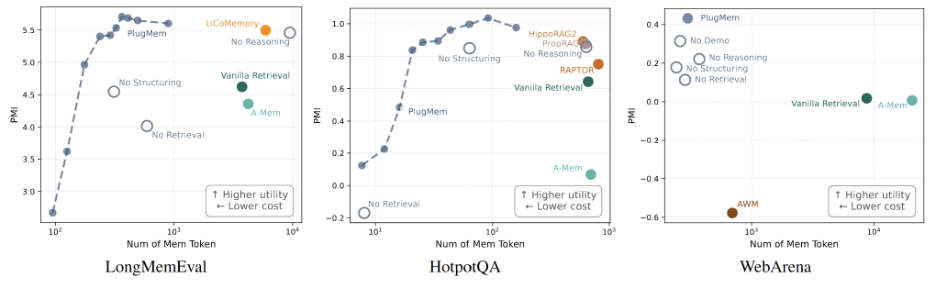
The efficiency gains come from two sources. First, structured knowledge is more compact than raw text. A single prescriptive knowledge unit can replace hundreds of raw trajectory tokens. Second, the retrieval system is precise. It finds exactly the knowledge needed without dragging in irrelevant context.
Comparison With Other Memory Systems
Several other memory systems have been proposed recently. Understanding how they differ from PlugMem helps clarify its unique value.
GraphRAG organizes information around entities and relationships. It is good for factual retrieval but struggles with procedural knowledge. The unit of access is a text chunk or entity, not an actionable insight.
Zep uses a temporal knowledge graph with validity dates. It tracks when facts become true or false. This is useful for conversational agents but requires a graph database and has an opinionated schema.
Letta, formerly MemGPT, makes memory a first-class agent component. It uses core memory blocks in the prompt and archival memory in a database. The agent calls tools to retrieve from memory. This is transparent and controllable but requires manual memory block management.
PlugMem differs from all of these by treating knowledge as the fundamental unit. It does not just store what happened. It stores what the agent learned. This makes the memory transferable across tasks and more efficient to retrieve.
Real-World Applications
PlugMem is designed for practical deployment. The plugin architecture means it can be added to existing agents without rewriting the core system. The May 2026 plugin release includes integrations for OpenClaw and Claude Code, with features like memory graph inspection and interactive retrieval testing.
For customer service agents, PlugMem can remember user preferences and successful resolution strategies across thousands of conversations. The agent does not need to re-learn these patterns for each new ticket.
For research assistants, PlugMem can accumulate domain knowledge and research methodologies. The agent learns which sources are reliable, which search strategies work, and how to synthesize findings.
For personal assistants, PlugMem can build a rich model of the user’s habits, preferences, and goals. This knowledge persists across sessions and improves over time.
Limitations and Future Work
PlugMem is not perfect. The structuring module relies on LLM inference, which adds cost and latency. The quality of extracted knowledge depends on the quality of the raw trajectories. Bad data leads to bad knowledge.
The current implementation focuses on text-based interactions. Multimodal memory that includes images, audio, and video is an open challenge. The researchers plan to extend PlugMem to handle these richer data types.
Another limitation is conflict resolution. When new knowledge contradicts old knowledge, PlugMem needs better mechanisms to decide which to keep. Temporal validity tracking, similar to Zep’s approach, could be integrated.
Final Thoughts
PlugMem represents a fundamental shift in how AI agents remember. Instead of storing raw logs and hoping the right information emerges at retrieval time, it actively distills experience into reusable knowledge. This makes memory more efficient, more transferable, and more useful.
The task-agnostic design is particularly important. As AI agents take on more diverse roles, they need memory systems that can keep up. A memory module that works for shopping, research, and customer service without custom engineering is a significant step forward.
For developers building agent systems, PlugMem offers a practical path to better memory. The code is open source. The plugins are available. The paper provides full implementation details. The future of AI memory is not about remembering more. It is about remembering better.