The creators of SWE-Bench just released a new, extremely difficult benchmark. The results are truly shocking: Claude Opus 4.7, GPT-5.4, GPT-5 mini, Gemini 3.1 Pro, and Gemini 3 Flash—almost all of the strongest top-tier models of this generation—scored 0% completion rate.

Not a single model could completely rebuild a software project. What does this mean?
The Gap Between Coding and Software Engineering
oday’s large language models are already very good at writing code, but they still don’t know how to do software engineering. Recently, Meta FAIR, together with Stanford, Harvard, and other institutions, published a fascinating new benchmark. It is essentially redefining how we evaluate AI coding abilities:
ProgramBench: Can Language Models Rebuild Programs From Scratch?

Previous coding benchmarks for large models mostly tested local abilities: completing a function, fixing a bug, or implementing a single feature. Essentially, these tests were still about making local changes within an existing code structure.
But ProgramBench pushed the question to the real level of software engineering for the first time: If you only give an AI a program’s functional description and usage documents, can it act like a real engineer and rebuild a real, executable software system from zero?
The projects include complex systems like FFmpeg, SQLite, and ripgrep—and importantly, the AI cannot search the internet.
Simply put, the question is: “Does the model really have engineering intelligence?”
To test this, the research team directly deleted the original source code and test files. They only kept the executable program and the usage documents. The model needs to decide on the programming language, the architecture, how to split modules, the data structures, and even how the entire repository should be organized.
Even more importantly, ProgramBench does not grade based on how similar the code is to the original. Instead, it uses “behavioral equivalence”. This means you can use a completely different language, algorithm, architecture, or engineering approach. As long as the final input and output behavior matches the original program, it counts as a pass. The research team even used agent-driven fuzzing to automatically generate a large number of end-to-end behavior tests.
This is the first time a benchmark has truly started to approach real-world software engineering, rather than just solving coding problems.
The Stunning Results
After the results came out, the entire AI community fell silent.
All models: 0% completion rate.
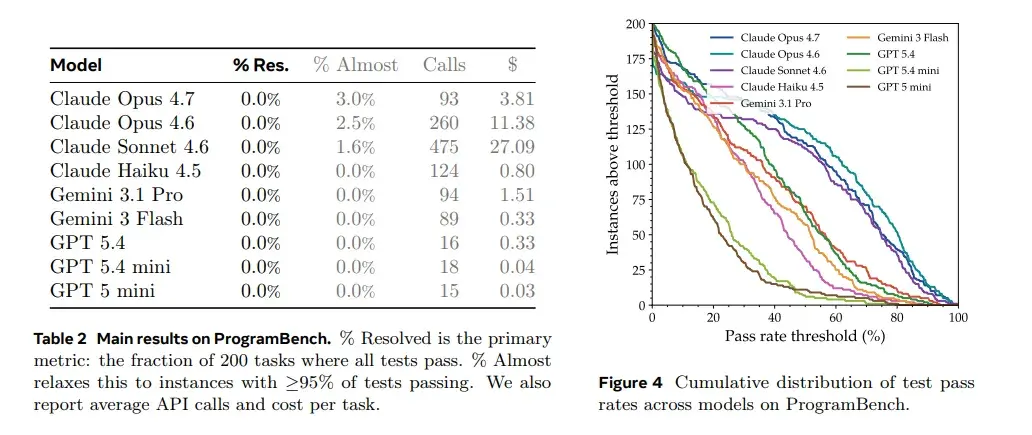
If the data tables created the shock, the detailed charts help explain it. They tell us that models aren’t completely incapable. They can often build parts of the system, and in a few tasks, they even come close to finishing.
However, as soon as you require 100% behavioral equivalence, all models collapse. This “last mile” is exactly the biggest difference between software engineering and simple code generation.
If we have to pick the best from the group, the Claude series (especially Opus 4.7 and 4.6) performed relatively better than others.
Even when the paper added a special metric called “Almost”—counting tasks that were over 95% completed—the strongest model, Claude Opus 4.7, only managed to come close to finishing just 3% of the tasks.
A Critical Flaw Exposed
There is a particularly key sentence in the paper:
“Models favor monolithic, single-file implementations that diverge sharply from human-written code.”
This exposes a core problem: AI is good at generating local code, but it is not good at global system planning. Real software engineering is essentially about the latter.
This explains why models are already very strong in LeetCode, SWE-Bench, and GitHub Copilot scenarios. But once they enter real-world, large-scale engineering systems, they quickly fall into deep trouble.
The real bottleneck for AI coding today is no longer code generation capability. It is the capability for long-term software system construction.
Performance Differences Across Languages
Another interesting result is the difference in performance across different programming languages.
The research team separately measured how models performed on projects in C/C++, Go, Rust, and other languages. You can clearly see that traditional C/C++ projects had the highest completion rates, while Rust performed the worst.
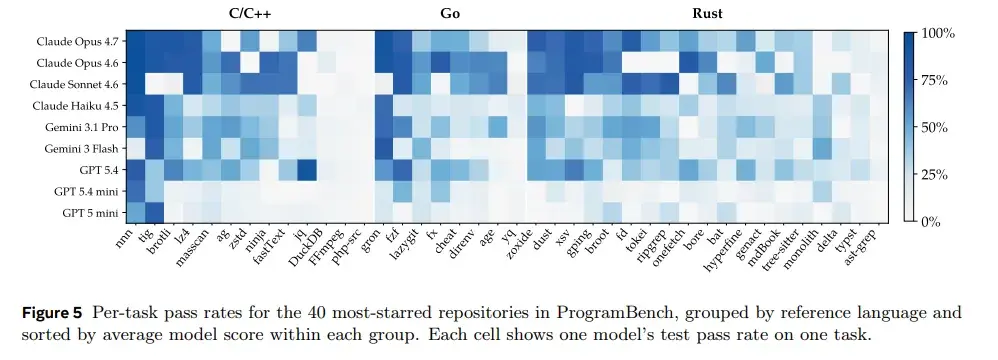
The ranking of difficulty was highly consistent across different models. For simpler CLI tools like nnn, fzf, and gron, models generally achieved higher pass rates. But for complex systems like FFmpeg, php-src, typst, and ast-grep, almost all models struggled to make progress.
This shows that ProgramBench isn’t measuring a random failure by one model. It shows that complex software systems themselves are applying stable pressure that current models cannot handle.
This result isn’t actually surprising. The internet contains a massive amount of historical code, engineering practices, and Stack Overflow content for C/C++. Models have been “soaked” in these patterns for years.
In contrast, Rust’s engineering philosophy places more emphasis on modularity, ownership, trait systems, and long-term maintainability. These are exactly the things current models are worst at. In a sense, Rust isn’t testing coding ability; it’s testing engineering ability.
Controversy and Defense
As ProgramBench sparked heated discussions, debates around this benchmark quickly spread.
One of the main criticisms is: “Isn’t this just testing whether the model has memorized FFmpeg?” After all, many projects in ProgramBench are publicly open-source software.
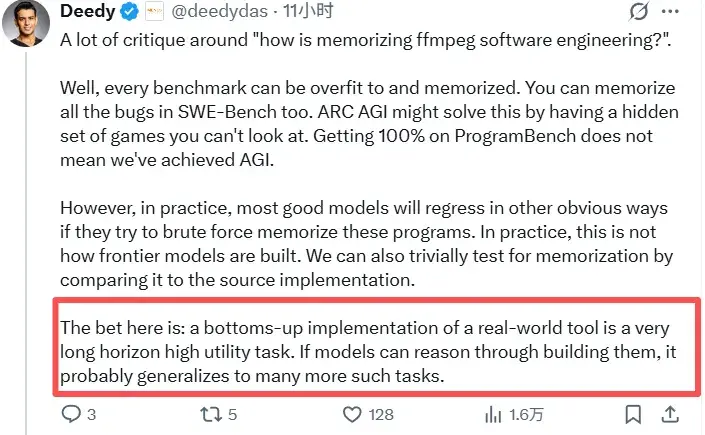
SWE-Bench can be memorized for bugs. LeetCode questions can be memorized. Even ARC-AGI might need hidden question banks in the future to avoid data leakage. Simply discussing whether memorization exists doesn’t actually deny the value of the benchmark.
The researchers argue: If a model really tries to use brute force to memorize these programs, it will often obviously degrade in other areas. Real large model training isn’t about stuffing the entire FFmpeg codebase into its parameters. Furthermore, researchers can detect direct memorization by comparing the similarity between generated code and original source code.
What they really want to emphasize is that rebuilding a real-world software system from scratch is itself a highly useful, long-time-span complex task. If a model can truly reason through and complete such tasks, this ability will likely generalize to many other engineering scenarios.
Another type of controversy is more interesting. Some people complained: “Even humans can’t rewrite FFmpeg from scratch. This benchmark is simply unreasonable.”
Deedy Das responded: So what? Today, many LLMs can do things that average humans cannot.
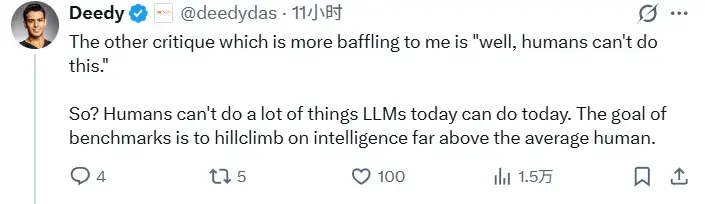
The goal of a benchmark is never to simulate the average ability of ordinary people, but to push models toward higher levels of intelligence. “Humans can’t do it” doesn’t mean the benchmark has no value. For example, AlphaGo plays Go better than the vast majority of humans, but that didn’t stop it from advancing AI. Similarly, a benchmark that sits far above the ability boundary of ordinary engineers may be the exact problem future Agent systems must conquer.
Of course, he admits ProgramBench still has many flaws. For example, it currently doesn’t test complete agent harnesses like Claude Code or Codex. It only counts whether the task is finished, without finely measuring progress. It also restricts internet access to avoid obvious cheating.
What’s Truly Important
What’s truly important is that ProgramBench is the first to pull AI coding evaluation from the function level up to the system level.
What it exposes is the biggest gap in the entire industry right now: Real software development has never been about writing one function. It’s about how to create an engineering system that can be maintained, extended, and collaborated on by a team.
Today’s large models are already very good at generating local code. But they still lack the ability to maintain complex systems in a long-term, consistent, and stable manner.
That’s why you’ll find that recently, the entire industry has started frantically researching a new set of keywords: memory, agents, repo-level reasoning, long-horizon planning, autonomous software engineering.
Because the competition in the next stage may no longer be about who can generate longer code in one go. It might be about who can maintain a living software system continuously and stably over long periods of time, multiple rounds of interaction, and complex contexts.
As AI moves forward, the challenge has shifted from “Can you write this function?” to “Can you build and maintain this entire system?”
The 0% completion rate isn’t a failure—it’s a wake-up call. It tells us exactly where the frontier lies. And that frontier isn’t about better syntax or faster completion. It’s about developing true engineering intelligence that can plan, organize, and sustain complex systems over time.
The industry has officially entered the era of system-level AI coding. And the race to build models that can truly engineer software—not just write code—has only just begun.