【AI Research Update】An AI without training gradients has broken the perfect score record in Atari games.
OpenAI clothes remover senior researcher Jiayi Weng has proposed a new reinforcement learning paradigm — Heuristic Learning (HL).
It uses no neural network training and no gradient updates. Instead, it relies on GPT-5.4-powered Codex to iterate autonomously, and achieved the theoretical perfect score of 864 in the classic game Breakout.

Unlike traditional deep reinforcement learning (DRL) that optimizes neural network parameters, HL does not use differentiable weights to store strategies. It moves decision logic to a discrete program space, replaces gradient descent with code editing, and uses clear symbolic rules to map states to actions.
In many tasks like games and robot simulations, this method even performs better than the classic reinforcement learning algorithm PPO.
Traditional DRL has long assumed that an agent’s decision core must be based on neural networks. For example, in a game, when the agent sees the ball is on the left, the neural network outputs the action “move left” through complex calculations. But the whole decision process is a black box — no one can clearly understand the internal logic. We can only use gradient descent to blindly iterate and fit the data.
Because of this design, DRL has three big unsolved problems.
First, catastrophic forgetting. Neural networks store learned skills in parameters. When training on a new task, the gradient updates will overwrite old weights, so the agent cannot learn multiple tasks continuously.
Second, unexplainable decisions. Every action the agent takes is hidden in millions of network weights and matrix operations. We cannot trace why the agent made that decision, and we cannot manually adjust or break down the logic.
Third, low sample efficiency. DRL needs huge amounts of interaction data with the environment to train. It takes a long time to converge and uses a lot of computing power, which makes research and deployment very expensive.
HL’s idea is simple: if parameter updates are the problem, just don’t use parameters. It turns the agent’s decision strategy from neural network weights into readable code. Learning becomes editing code instead of optimizing gradients.
In the HL framework, the AI does not maintain a single strategy file. It maintains a complete intelligent software system: clear state detectors (like “the ball is in the top left, moving right”), clear rule logic (like “if the ball will land on the left, move left”), plus test cases, regression checks, failure records, and version history.
Every iteration, Codex looks at how the system performed, watches the failure videos, analyzes the logs, and makes structural changes.
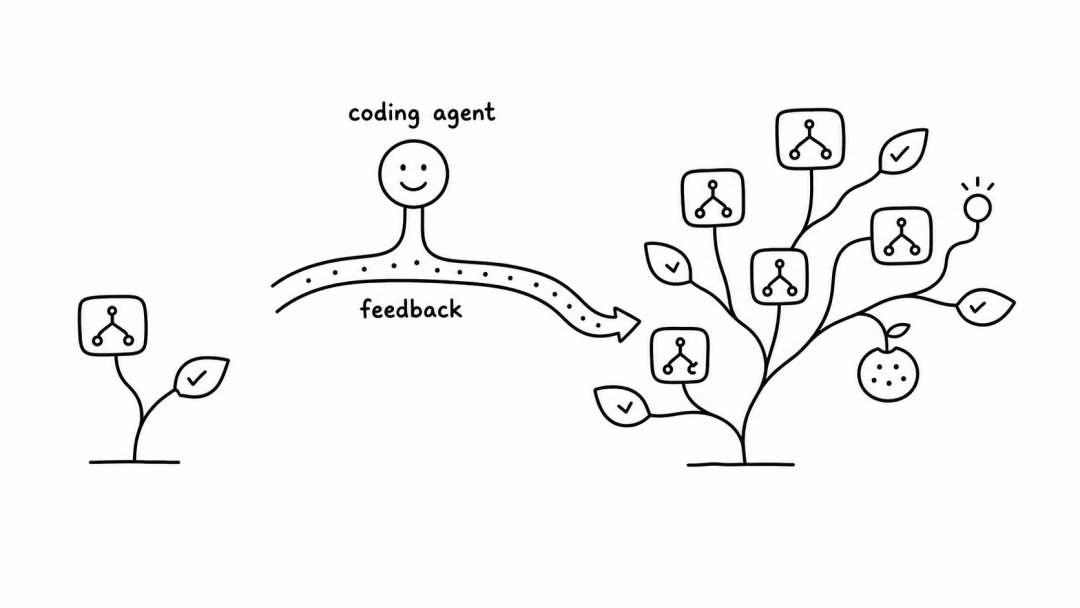
The key advantage of this paradigm is that knowledge is explicit. Old skills are not overwritten. They are packaged into modules and tests, so you can call them, verify them, and pass them on at any time.
As Jiayi Weng said: “HL changes continuous learning from ‘how to update parameters’ to ‘how to maintain a software system that keeps absorbing feedback’.”
Of course, HL does not completely reject gradient technology. Some of its internal components, like Model Predictive Control (MPC), still use gradients for local search. But the important thing is that these gradient operations are not used for neural network training or parameter updates. They only help with real-time action decisions.
This design makes HL naturally explainable, resistant to forgetting, and efficient.
HL didn’t just get a perfect score in Breakout. Jiayi Weng completed a full test on the Atari 57 benchmark — a widely used reinforcement learning test set with 57 different classic games, covering all kinds of discrete decision scenarios. Each game was tested in two observation modes, with three rounds each. In total, 342 independent code iteration tracks were generated.
The results show that with the same number of environment interaction steps, HL’s overall median performance is already equal to mainstream DRL algorithms like PPO. In games like Breakout, Asterix, and Jamesbond, it even outperforms human players.
Robot simulation tasks are harder ai porn gen than game decisions. For example, the four-legged robot Ant needs to control 8 joints at the same time to keep balance in a high-dimensional continuous action space. HL started with basic gait rules, and gradually added posture feedback, ground contact sensing, and short-term model prediction. Finally, it scored over 6000 points, matching the performance of professional DRL models.

In the HalfCheetah simulation task, HL got an average score of 11836, showing its strong ability to handle complex continuous control scenarios.

But Jiayi Weng also talked about the limits of HL. He said: “As far as I know, I can’t think of an agent that can write pure Python code without neural networks to solve ImageNet.”
Object recognition and feature extraction from raw pixels are still the strengths of deep neural networks, and they cannot be replaced.
The main value of HL is in continuous strategy iteration. When the environment changes dynamically and the agent needs to adjust its behavior over time, the explicit code rule system is better for continuous learning.
So the key question now is how to combine neural networks and HL to solve both online learning and continuous learning problems. Jiayi Weng pointed out the most promising approach: use HL to process real-time online environment data and quickly accumulate reusable behavior experience. Then organize these explicit experiences into high-quality datasets, and use them to periodically update the neural network.