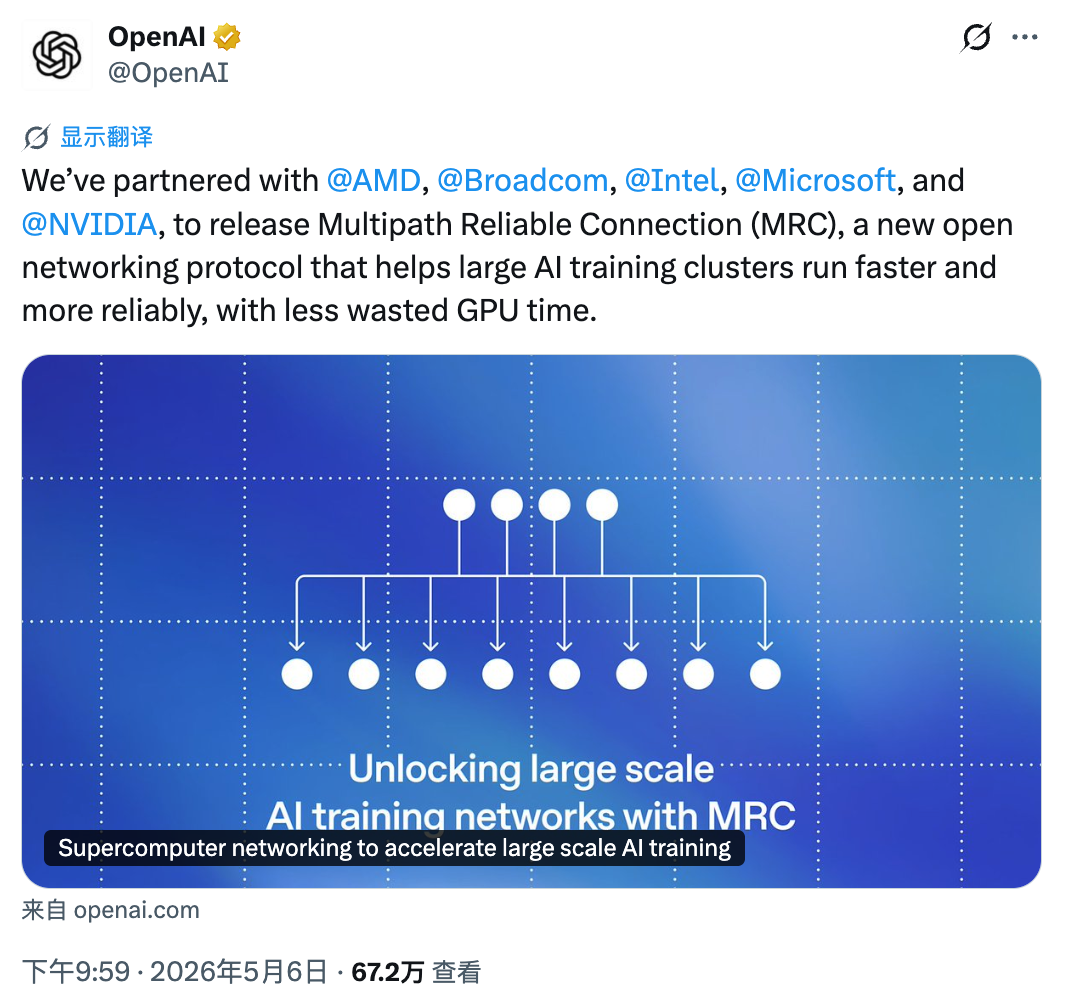
OpenAI has released a new networking protocol that could change how large AI models are trained. The protocol is called MRC, which stands for Multipath Reliable Connection. It was developed in partnership with AMD, Broadcom, Intel, Microsoft, and NVIDIA. The goal is simple. Make GPU clusters more stable, faster, and cheaper to build.
Training modern AI models requires thousands of GPUs working together. When one GPU fails or a network link slows down, the entire training job can stall. Current networking protocols struggle with this problem. MRC solves it by spreading data across hundreds of network paths at once and recovering from failures in microseconds.
Why Networks Break at Scale
Training a large AI model is not just about compute power. It is cuck chat also about moving data between GPUs quickly and reliably. A single training step can involve millions of data transfers. If one transfer arrives late, the entire job can slow down or crash.
Network congestion, link failures, and switch problems are the most common causes of delay. These issues get worse as clusters grow. A 2026 study found that the mean time to failure for a 1,024-GPU cluster in a shared cloud is just 0.33 days. That means a training run is interrupted almost every eight hours. Each interruption requires reloading from a checkpoint, which can take hours.
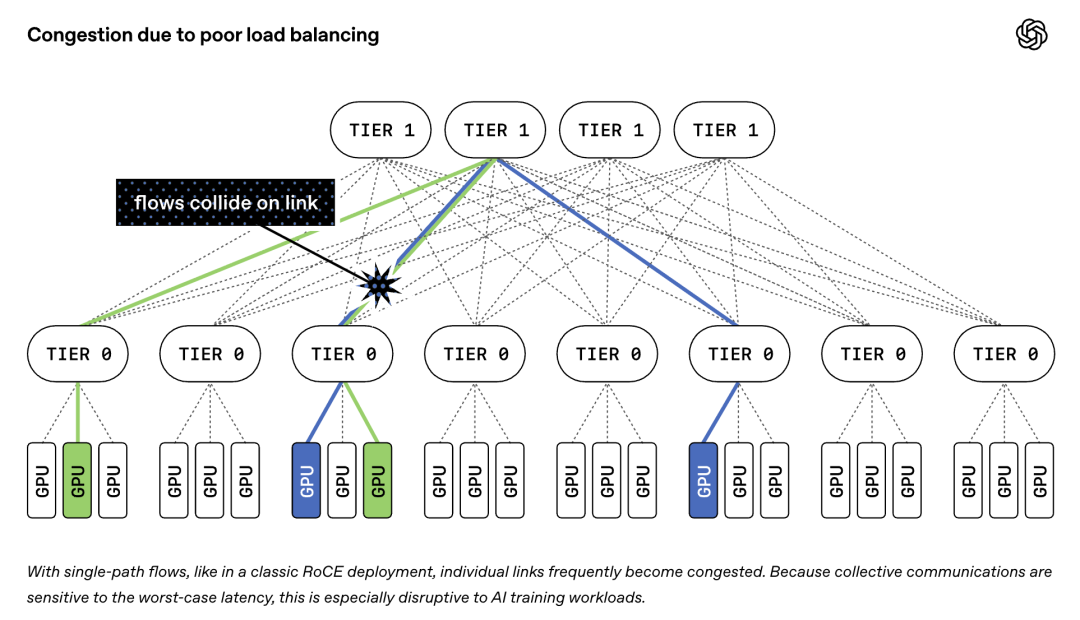
Traditional networking protocols like RoCEv2 send each data transfer over a single path. If that path gets congested or fails, the transfer stalls. This creates a bottleneck that wastes GPU time and money.
How MRC Works
MRC uses three key mechanisms to solve these problems.
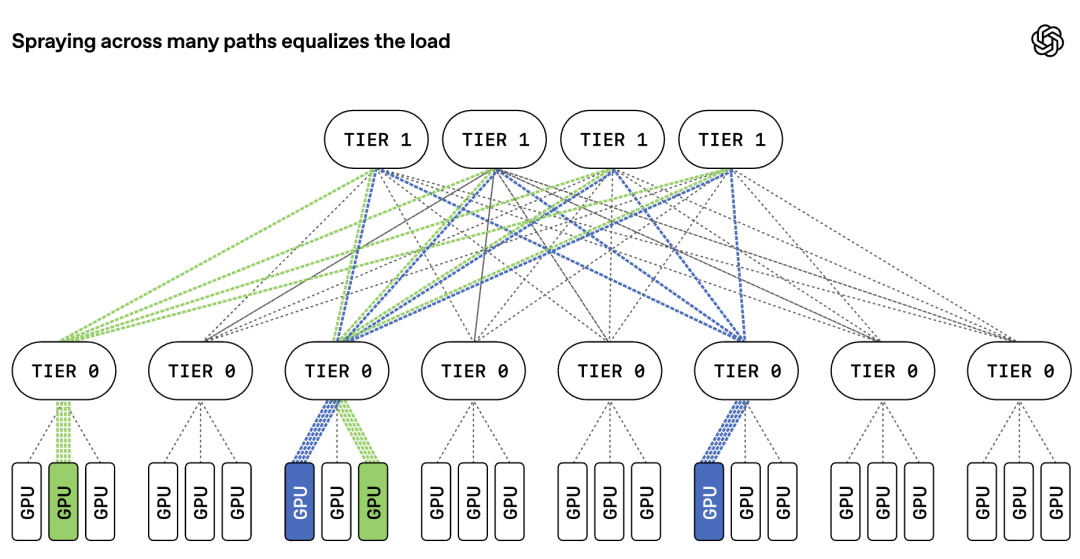
First, adaptive packet spraying. Instead of sending all packets for one transfer down a single path, MRC spreads them across every available path in the network. If one path is congested or broken, packets simply flow through other paths. The receiving end reassembles them in the correct order. This virtually eliminates congestion in the core of the network and keeps all paths busy.
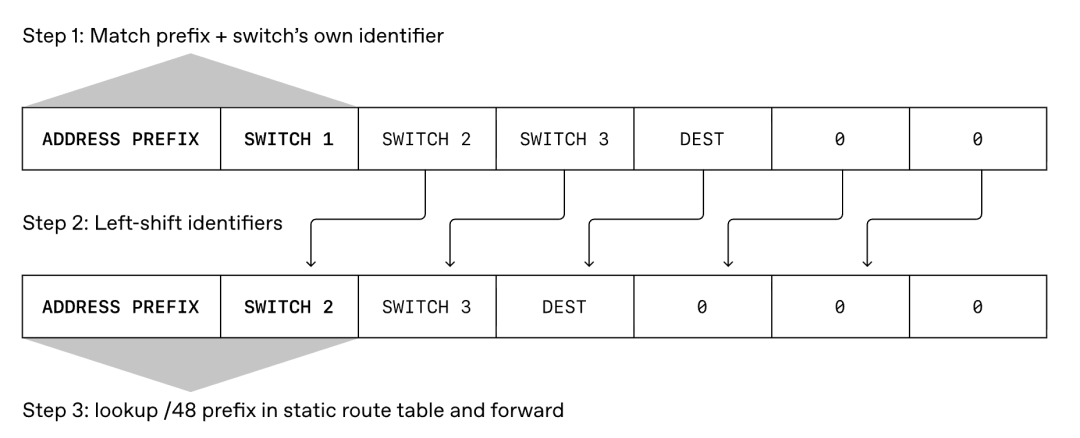
Second, microsecond-level failure recovery. MRC uses a technology called SRv6 source routing. The sender puts the exact route inside each packet header. Switches do not need to run complex routing calculations. They just forward packets along the pre-set path. If a link fails, MRC detects it instantly and reroutes traffic around the problem. Recovery happens in microseconds rather than seconds.
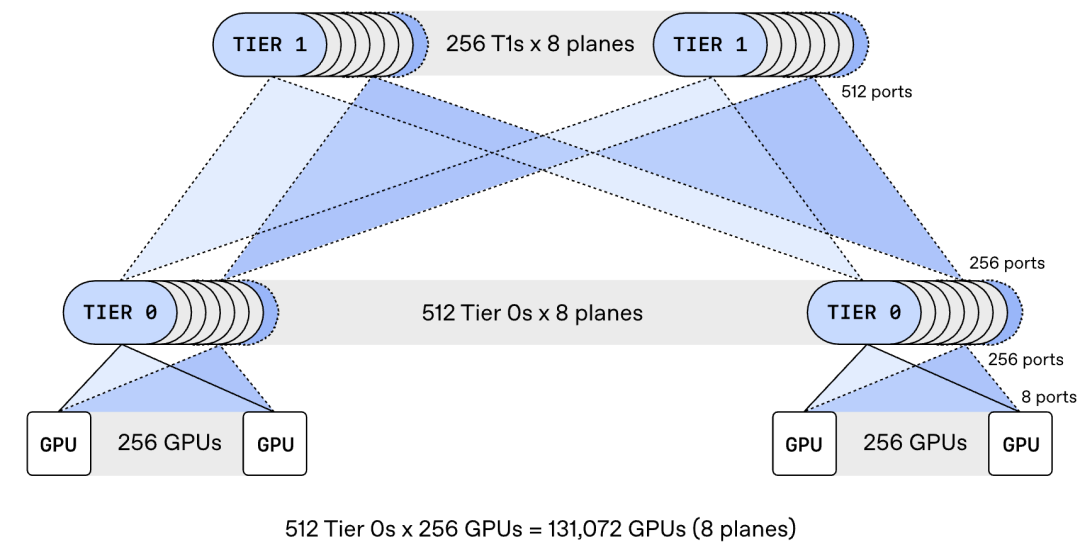
Third, multi-plane network design. MRC splits each 800Gb/s network interface into multiple smaller links. For example, one interface can become eight 100Gb/s connections to different switches. This allows a cluster of about 131,000 GPUs to connect with only two tiers of switches. Traditional designs would need three or four tiers. Fewer tiers means lower cost, less power, and shorter delays.
The Numbers Behind MRC
The cost savings from MRC are significant. Research shows that for full bisection bandwidth, a two-tier multi-plane design needs only two-thirds of the optics and three-fifths of the switches compared to a three-tier network. The longest path traverses just three switches instead of five or seven. This reduces both latency and the blast radius when something fails.
MRC is already in production use. OpenAI has deployed it on NVIDIA GB200 supercomputers at Oracle Cloud Infrastructure and Microsoft. These clusters have been used to train frontier large language models for ChatGPT and Codex. According to OpenAI, MRC has helped avoid much of the typical network-related slowdowns and interruptions that plague large training jobs.

How MRC Handles Failures
Network failures are inevitable in large clusters. A cable gets unplugged. A switch reboots. A port degrades. MRC is designed to handle these problems without stopping training.
Before MRC, if a link between a GPU’s network card and a switch failed, the training job would crash. With MRC, the job continues. If an 8-port network card loses one port, the maximum speed drops by one eighth. MRC detects this, recalculates paths to avoid the failed plane, and tells other GPUs not to use that plane. Most failed links recover within a minute. When they do, MRC brings the plane back into service automatically.
This resilience comes from a deliberate design choice. All routing intelligence lives at the network card level, not the switch level. Switches run simple static routes. They do not need to recompute paths when something changes. This prevents two adaptive systems from interfering with each other.
SRv6 Source Routing
MRC replaces traditional dynamic routing protocols like BGP with SRv6 static source routing. In traditional networks, switches constantly exchange routing information and recalculate paths. This takes time and creates complexity.
With SRv6, the sender decides the route and writes it into the packet. Switches simply follow the instructions. There is no dynamic state in the switches. No routing tables to update. No convergence delays when links fail. The network control plane becomes simple and predictable.
This approach also improves security and observability. Because routes are static, operators know exactly how traffic flows. They can debug problems more easily. They can also prevent routing loops and other common network failures that dynamic protocols sometimes create.
Industry Adoption
MRC is not just a research project. It is already being implemented by major hardware vendors.
NVIDIA has added MRC support to its Spectrum-X Ethernet platform. AMD has implemented MRC in its Pensando Pollara 400 and Vulcano 800 AI network cards. Broadcom has integrated it into Thor Ultra network chips. These implementations mean MRC will be available in production hardware from multiple vendors.
The protocol was released through the Open Compute Project, an industry group that promotes open standards for data center infrastructure. This ensures that any company can use MRC without paying royalties or depending on a single vendor.
What This Means for AI Infrastructure
The release of MRC signals a shift in how AI training clusters are built. For years, the industry has focused on adding more GPUs. Now the focus is shifting to making better use of the GPUs already installed.
Network reliability is the hidden bottleneck in large-scale AI training. A cluster with 100,000 GPUs is only as fast as its slowest network link. If failures cause frequent interruptions, the effective training speed drops dramatically. Some studies show that model flops utilization can fall to 35 to 45 percent in unstable clusters.
MRC addresses this by making the network more resilient. It reduces the impact of individual failures. It keeps traffic flowing even when parts of the network are down. It simplifies operations by eliminating complex dynamic routing.
For companies building AI infrastructure, MRC offers a path to lower costs and higher reliability. The two-tier design reduces the number of switches and cables needed. The multi-plane architecture provides redundancy without extra hardware. The open standard prevents vendor lock-in.
Comparison With Traditional Approaches
Traditional AI clusters use InfiniBand or standard Ethernet with RoCEv2. InfiniBand offers high performance but requires specialized hardware and is expensive. Standard Ethernet is cheaper but struggles with congestion and failures at scale.
MRC aims to bridge this gap. It runs on standard Ethernet hardware but adds the reliability features that InfiniBand provides. By using packet spraying and source routing, MRC achieves performance comparable to InfiniBand while keeping the cost and flexibility of Ethernet.
This could change the competitive landscape. NVIDIA has dominated AI networking with its InfiniBand and Spectrum-X products. MRC gives other vendors like AMD and Broadcom a way to compete on equal terms. It also gives cloud providers more options for building custom AI infrastructure.
Technical Deep Dive
For readers who want more detail, here is how MRC works under the hood.
Multi-plane topology. A standard 800Gb/s network interface is split into eight 100Gb/s lanes. Each lane connects to a different switch. This creates eight independent network planes. A switch with 64 ports at 800Gb/s can instead support 512 ports at 100Gb/s. The result is a two-tier network that connects 131,072 GPUs.
Adaptive packet spraying. MRC extends the standard RoCEv2 protocol with intelligent load balancing. It sprays packets from each connection across all available paths. If a path becomes unusable, packets automatically flow to other paths. The receiving network card reorders packets and delivers them to the application.
Selective acknowledgment. Traditional protocols use go-back-N recovery, which retransmits an entire window of packets when one is lost. MRC uses selective acknowledgment and negative acknowledgment to retransmit only the lost packets. This reduces recovery time and network overhead.
Network-signaled congestion control. MRC implements a congestion control mechanism based on the Ultra Ethernet Consortium specification. It uses path-aware sender-based control so congestion is managed at the path level rather than the network level. Round-trip-time-aware window control adjusts sending rates based on network conditions.
Final Thoughts
OpenAI’s release of MRC is a significant contribution to AI infrastructure. By open-sourcing a protocol that has already been proven in production, the company is helping the entire industry build more reliable and efficient training clusters.
The timing is important. As AI models grow larger and training runs extend for months, network reliability becomes critical. A single failure can waste weeks of compute time and millions of dollars. MRC reduces this risk by making networks more resilient and failures less disruptive.
For the broader tech industry, MRC represents a step toward open standards in AI networking. It gives companies alternatives to proprietary solutions. It enables competition and innovation. And it ensures that the infrastructure powering AI remains accessible to organizations of all sizes.
The paper and technical details are available on the OpenAI website. Hardware vendors are already implementing MRC in their products. The next generation of AI supercomputers will likely use this protocol or something inspired by it. The future of large-scale undress ai promo code AI training just got a little more stable.