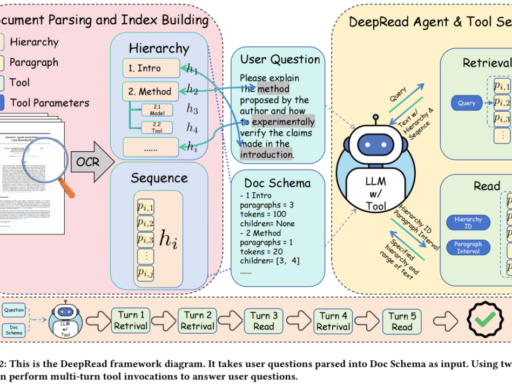
A new era of AI testing has arrived. For the first time, researchers are asking AI agents to solve real engineering problems that have no standard answers. This is a completely different challenge from answering trivia questions or passing multiple-choice exams. It is about whether AI can think like an engineer when faced with messy, open-ended problems.
Current AI agents can write code and search for knowledge. But real engineering is not about knowing facts. It is about making judgment calls.
Real engineering problems are messy. They involve trade-offs between stability and cost. They require balancing battery life against performance. They demand choosing between different materials, different designs, and different risks. There is no single right answer. There is only a better or worse solution based on the specific situation.
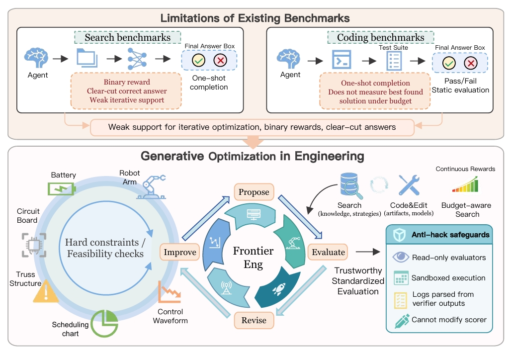
Recently, Einsia AI and Navers Lab released the Frontier-Eng Bench. This new benchmark is changing how we measure AI agent capabilities.

The research team did not want AI to simply memorize old exam questions. Instead, they created something new. They designed a closed-loop engineering system where AI must continuously improve its own solutions through real feedback.
These 47 engineering tasks are not puzzles with fixed answers. They are the kind of problems that senior engineers spend weeks solving. They require a full understanding of the system. They demand creative exploration and iterative improvement.
This is not just a harder test. It is a fundamental shift in how we evaluate AI agent intelligence.
When AI first learned to write code, the goal was simple. Make the AI produce correct code within 24 hours. But in the Auto Research era, we are asking much more from AI systems.
Previous large models had a fatal weakness. When faced with a problem, they would search their memory for similar examples. Then they would patch together an answer from bits and pieces they had seen before.
In this mode, the model is essentially doing pattern matching. It is not really solving the problem.
The arrival of Frontier-Eng Bench breaks this pattern. It forces AI into a continuous optimization loop.
Think about it. Real engineering work involves simulators, physical experiments, design iteration, parameter adjustment, and error correction. It requires multiple rounds of testing and improvement until the solution actually works.
In this closed-loop system, AI learns from feedback over time.
To some extent, AI has already crossed the line from being a tool to being a professional engineer. It is no longer just writing code. It is designing systems, running experiments, and optimizing results.
ai celebrity nudes
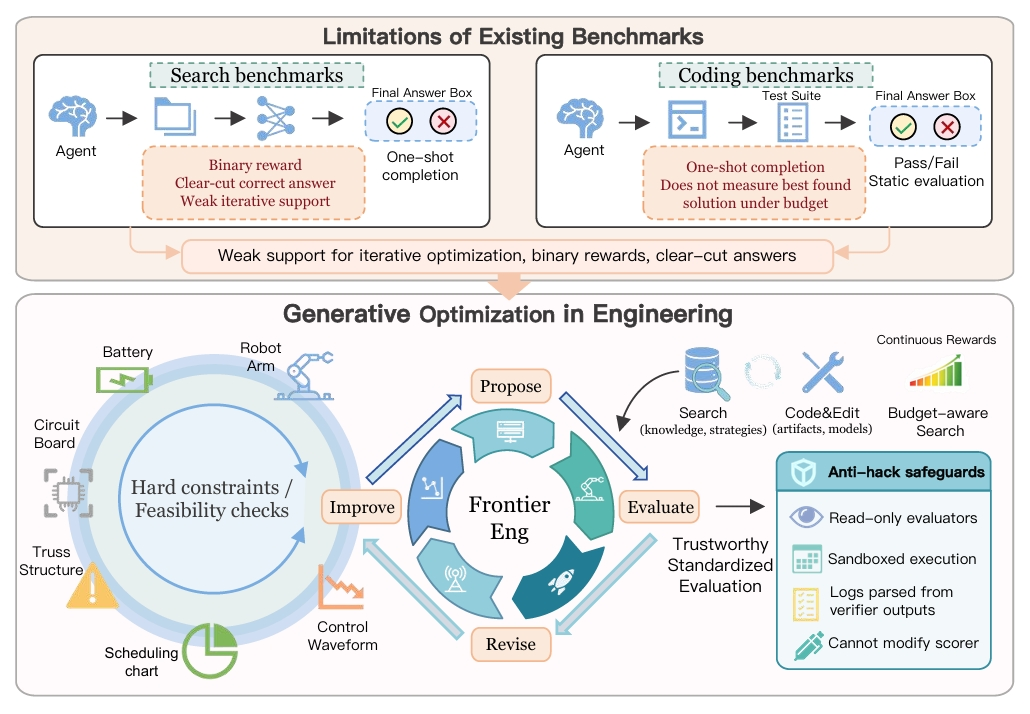
Frontier-Eng Bench Overview
The most important thing about Frontier-Eng Bench is that the tasks have no standard answers. This tests whether AI can truly think rather than just memorize.
Because real engineering optimization is about making choices. There is no single correct answer.
The test questions look simple at first. The better the AI performs, the harder it gets.
AI agents cannot pass by simply cumshot ai memorizing answers. They must handle complex constraints. They need to balance multiple factors like battery life, heat management, and cost. They must find the best solution through continuous optimization.
This means AI cannot cheat by memorizing test questions. It must demonstrate real engineering thinking during the problem-solving process.
Can AI really do continuous engineering optimization.
From current results, even GPT-5.4 and similar top models still have a long way to go on this benchmark.
ai porn gen
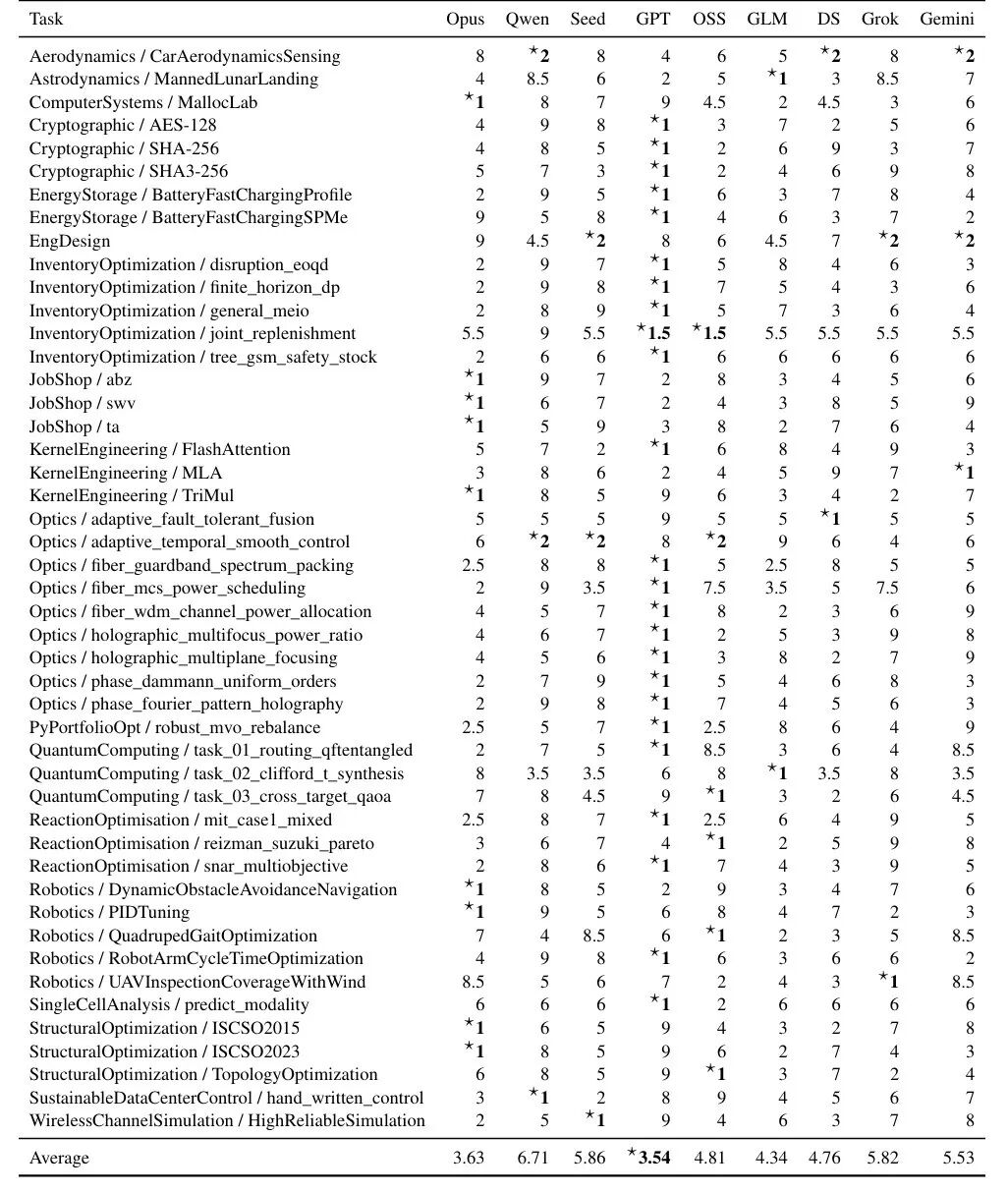
Performance Comparison of Different Models
The research team discovered a very interesting pattern.
First, the logic of exploration and exploitation exists in every engineering optimization.
Since AlphaGo, we have known that search and exploration are essential. Every move involves choosing between trying something new and sticking with what works. This requires both stable strategy and creative risk-taking.
Engineering projects are the same. Each experiment is not a single test but a continuous process of exploration, experimentation, and learning from failure.
Second, optimization itself is a social process. It involves collaboration between different experts. In reality, less than 1 percent of solutions come from a single brilliant idea. Most progress comes from gradual improvement.
Frontier-Eng Bench captures this reality. For the first time, it systematically tests AI continuous optimization ability. This gives us a real way to measure whether AI agents can grow and improve.
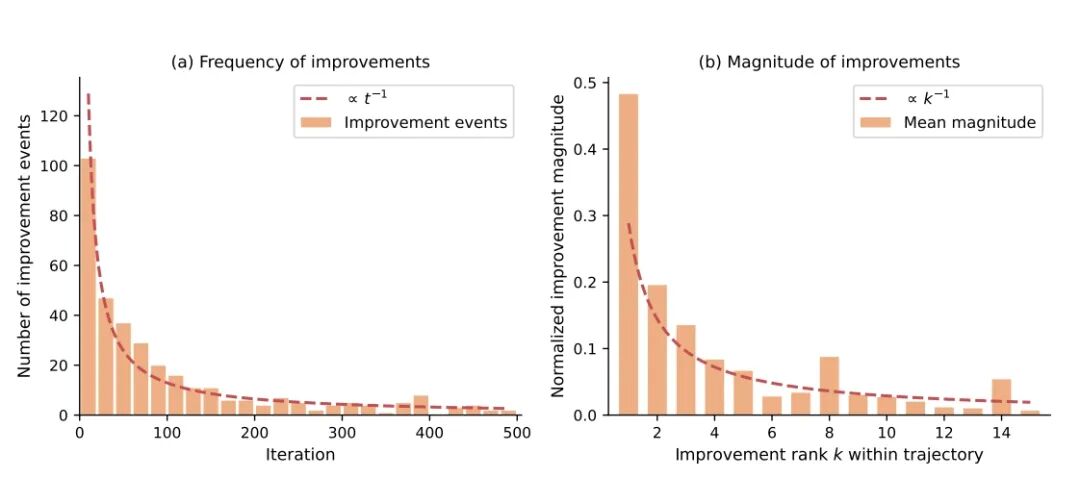
Optimization Double Descent Curve
Another surprising finding is that more parameters do not always mean better performance.
According to the paper analysis, the frequency and amplitude of agent improvements show a double descent pattern.
In simple terms, the first few iterations show quick wins. But then it gets harder and harder. The improvements become smaller and smaller.
In real engineering practice, an AI might quickly find an obvious bug and fix it. But as it gets closer to the optimal solution, each improvement requires deeper understanding. It is like climbing a mountain. The higher you go, the harder each step becomes.
Does this mean we should explore multiple paths and choose the best one. The answer lies in the second key finding.
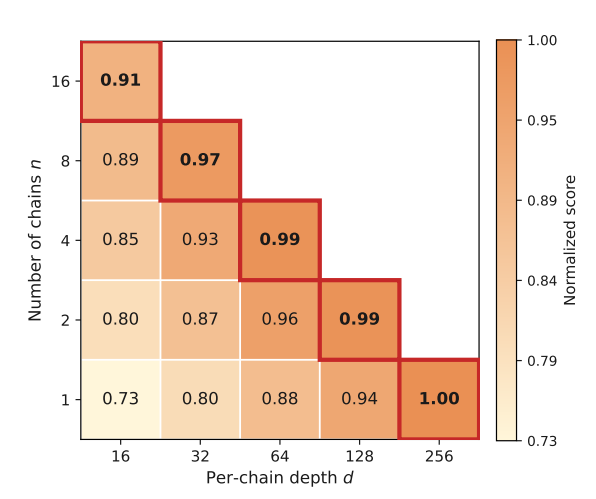
Exploration vs Exploitation
The second key finding is about collaboration. Multiple agents working together perform better than single agents.
Many engineering tasks are like escape rooms. When predicting the future, opening one door creates pressure to open another. Different functions need to work together. The optimization process involves structural migration, knowledge sharing, and collaborative implementation.
This reveals a key direction for agent development. It is not about a single model giving one answer. It is about building an engineering ecosystem where multiple AI systems collaborate, iterate, and improve together.
The research team gave this system a far-reaching name. They called it an AI system that starts from daily engineering practice and gradually approaches real-world complexity.
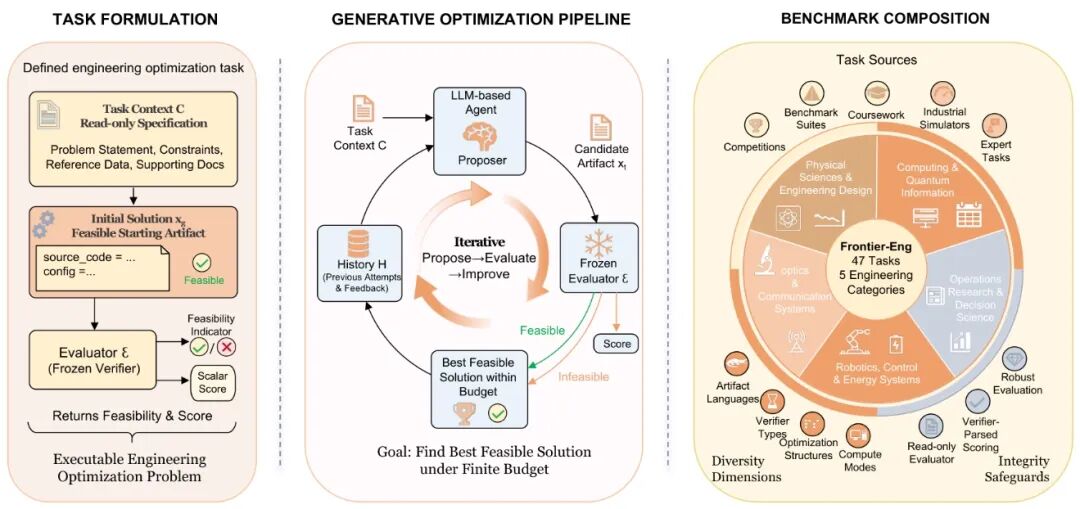
Frontier-Eng Bench Task Categories
Specifically, AI needs to work with industrial simulation environments. This includes CAD systems, chip design tools, and optical simulation platforms.
Another critical dimension is cross-modal reasoning.
In real engineering, this will likely become a standard requirement.
The research team set an ambitious goal.
For example, if an AI can help reduce GPU memory usage by 30 percent, or optimize chip layout to reduce heat generation, or improve the stability of autonomous driving systems, or balance the load across distributed systems. These are all real engineering challenges.
The path for AI agents is not about replacing humans in these goals. It is about continuous optimization.
This means automatic experiment execution, automatic verifier and simulator acquisition, iterative modification and optimization, and 24-hour non-stop operation.
At the logic level, AI agents have already crossed the line from tools to teammates. They are starting to form real engineering teams that can independently discover system problems and fix them without human help.
Frontier-Eng Bench is not just a benchmark. It is also a straightforward statement.
When AI learns continuous optimization, its real engineering capabilities are still far from what we need.