A new paper at ICLR 2026 is shaking up the world of time series forecasting. It is called CPiRi, short for Channel Permutation-Invariant Relational Interaction. The name is a mouthful, but the results are simple to understand. CPiRi tops the leaderboards on multiple benchmarks. It uses only 25% of the training data that other models need. And its performance stays stable even when channel order changes completely. That last point is the real breakthrough. For years, researchers have argued about two approaches to multivariate time series forecasting. One group says channels should be processed together. Another group says each channel should be handled separately. CPiRi says both sides are wrong. And it proves it with numbers.
Let us break this down in plain English.

Multivariate time series forecasting, or MTSF, is a fancy term for predicting the future when you have many related data streams. Think of a smart city with thousands of traffic sensors. Or a power grid with monitors at every substation. Or a hospital tracking dozens of patient vital signs. Each sensor is a “channel.” The challenge is predicting what happens next across all channels at once.
For years, the field has been split into two camps. The Channel Dependent camp, or CD, believes all channels should be processed together. Models like Crossformer and iTransformer use attention mechanisms to capture relationships between channels. They treat the entire multivariate sequence as a single input. The idea is that channels influence each other, so modeling them together should give better results.
The Channel Independent camp, or CI, takes the opposite view. Models like PatchTST and DLinear process each channel separately. They argue that channel relationships are too noisy and unpredictable. By treating each channel as its own time series, these models achieve strong and stable performance. The trade-off is that they miss cross-channel patterns that could improve accuracy.
This debate has created a strange situation. CD models should theoretically perform better because they use more information. But in practice, CI models often win. Why? The answer lies in a hidden problem that neither side has fully addressed.
The Real Problem: Structure and Distribution Drift Together
The research team behind CPiRi, from Zhejiang University of Finance and Economics, identified a deeper issue. They call it Structural-Distributional Co-drift. This is not just one problem. It is two problems happening at the same time, and they make each other worse.
Here is what happens in the real world. A traffic monitoring system in a smart city has sensors at intersections, on highways, and in parking lots. The data from these sensors changes over time. New roads open. Old roads close. Traffic patterns shift. The spatial relationships between sensors change. This is structural drift.
At the same time, the statistical properties of each sensor change. Morning rush hour patterns shift. Weekend traffic looks different. Seasonal changes affect volume. This is distributional drift.
When both drifts happen together, existing models fail. CD models depend on fixed spatial relationships. When those relationships change, the model breaks. CI models ignore spatial relationships, so they avoid that problem. But they also miss useful cross-channel information that could improve predictions.undress ai tools
The result is what the paper calls the “position bias dilemma.” CD models need fixed channel positions to work. Change the order of channels, and accuracy drops sharply. CI models avoid position bias by ignoring channel order. But they sacrifice the ability to learn cross-channel relationships. It is a lose-lose situation.
How ai erotic smut CPiRi Breaks the CI-CD Deadlock
CPiRi solves this problem with a clever three-stage design. The key insight is that the model should learn channel relationships without depending on channel order. It should be able to handle any channel arrangement and still produce the same predictions.
Stage 1: Temporal Feature Extraction
First, CPiRi takes the raw multivariate time series input. For each channel, it uses a pre-trained temporal porn ai chat model called Sundial as a frozen feature extractor. Sundial is a state-of-the-art channel-independent model. By freezing its weights during training, CPiRi avoids a problem called “structural entanglement.” This happens when a model tries to learn both temporal patterns and channel relationships at the same time. The two learning tasks interfere with each other, hurting performance.
The frozen Sundial extractor turns each channel’s raw data into a set of patch-level features. These features capture temporal patterns like trends, seasonality, and anomalies. Because Sundial is frozen, these features are stable and reliable. They do not change during CPiRi’s training.
Stage 2: Permutation-Invariant Spatial Interaction
This is where CPiRi gets clever. The patch features from all channels are collected into an unordered set. The order of channels does not matter. What matters is the content of each feature.
![]()
CPiRi then applies a standard Transformer encoder block to this unordered set. The multi-head self-attention mechanism computes attention weights between all pairs of features. Because there is no fixed channel order, the attention weights depend only on feature similarity, not on position. This is the key to solving the position bias problem.
The attention mechanism naturally forms what mathematicians call a “symmetric aggregation.” It treats all channels equally. No channel gets special treatment because of its position. The result is a set of content-driven channel relationships that are robust to any channel ordering.
![]()
The computational complexity of this stage is linear in the number of channels. This is a huge advantage over full attention mechanisms, which scale quadratically. For systems with thousands of sensors, this efficiency difference matters.
Stage 3: Independent Prediction Generation
Finally, CPiRi takes the globally informed channel representations and feeds them back into the frozen Sundial decoder. Each channel gets its own prediction head. The predictions are generated independently, but each prediction is enriched with global spatial information from the interaction stage.
![]()
This three-stage design has a beautiful property. The temporal learning and spatial learning are decoupled. The frozen Sundial handles temporal patterns. The CPiRi interaction module handles spatial relationships. Each part does what it does best, without interfering with the other.
Channel Shuffling: The Secret Training Trick
CPiRi has one more trick up its sleeve. During training, the model uses channel shuffling to force itself to learn position-invariant relationships. Here is how it works.
![]()
In each training batch, the channels are randomly permuted. Channel 1 might become Channel 5. Channel 3 might move to position 10. The spatial interaction module sees a different channel order every time. But because the module is permutation-invariant, it produces the same relationships regardless of order.
This is a form of meta-learning. The model learns to adapt to any channel arrangement. It develops a “meta-skill” for understanding channel relationships that transfers to new channel configurations. When the model encounters a new system with different sensor layouts, it does not need retraining. It simply applies the meta-skill it learned during training.
From Permutation Invariance to Permutation Equivariance
The paper makes a deep mathematical point that is worth understanding. In multivariate time series forecasting, the model should have two properties. First, it should be permutation-invariant with respect to channel order. This means shuffling channels should not change the model’s internal relationships. Second, it should be permutation-equivariant with respect to predictions. This means if you shuffle channels, the predictions should shuffle in exactly the same way.
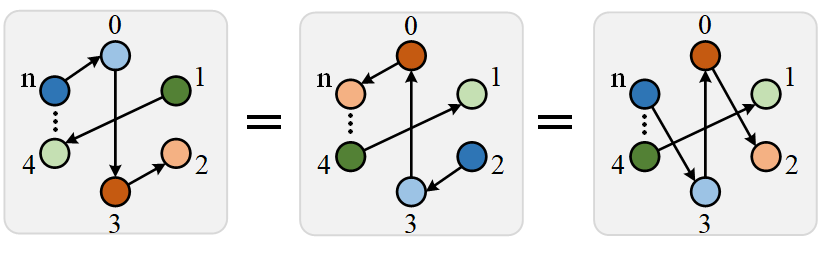
Think of it like this. If you have a photo of a face and you flip it upside down, the face is still the same face. The relationships between eyes, nose, and mouth do not change. That is permutation invariance. But if you want to predict where each feature will move in the next frame, your predictions should also flip upside down. That is permutation equivariance.
CPiRi achieves both properties. The spatial interaction module is permutation-invariant. It learns relationships that do not depend on channel order. The prediction generation module is permutation-equivariant. It maps each channel’s representation to its own prediction. Shuffle the channels, and the predictions shuffle accordingly.
![]()
The mathematical foundation comes from Deep Sets theory. Any permutation-invariant function can be decomposed into a symmetric aggregation. Self-attention, it turns out, is exactly such a function. The query-key-value mechanism computes pairwise similarities and aggregates values weighted by attention scores. This is a symmetric aggregation in disguise.
CPiRi’s success comes from combining two ideas. First, it uses channel shuffling during training to force the model to learn position-invariant relationships. Second, it uses self-attention’s natural symmetry to implement permutation invariance without extra complexity. The result is a model that is both simple and powerful.
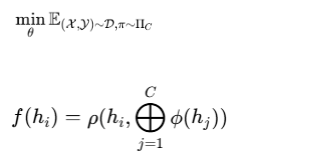
SOTA Results with Zero Performance Fluctuation
The experiments are where CPiRi really shines. The team tested on six standard benchmarks: METR-LA, PEMS-BAY, PEMS-04, PEMS-08, and SD. These are the same datasets that every MTSF paper uses. The evaluation followed the BasicTS+ protocol, which is the current standard for fair comparison.
Under standard fixed channel order, CPiRi set new state-of-the-art records on all benchmarks. It beat both CI and CD models. The improvements were not small margins. They were significant leaps.
On the SD dataset with 716 channels, CPiRi achieved a WAPE of 12.25%. The previous best, Sundial, scored 24.40%. That is a 12 percentage point improvement. On PEMS-08, CPiRi beat iTransformer by 9.43% versus 10.70%. These numbers prove that CPiRi’s approach of combining CI temporal modeling with CD spatial interaction works better than either approach alone.
But the real test was channel shuffling. The team randomly permuted channel order from 0% to 100% shuffled. For most CD models, this causes catastrophic failure. Informer on PEMS-08 saw its WAPE explode from 13.02% to 118.19% when channels were shuffled. STID jumped from 10.90% to 65.18%. These models are completely dependent on channel position.
CPiRi, with channel shuffling enabled, showed almost zero fluctuation. Even at 100% shuffling, its WAPE changed by less than 0.25%. That is not a typo. The performance was essentially flat. This proves that CPiRi has truly solved the position bias problem.
Zero-Shot Generalization: The Real World Test
Channel shuffling tests robustness. But the ultimate test is zero-shot generalization. Can the model predict on channels it has never seen before?
The team designed a hard test. During training, the model saw only 25%, 50%, or 75% of the available channels. During testing, it had to predict on all 100% of channels, including the ones it never saw during training. This is exactly what happens in real industrial systems. New sensors get added. Old sensors fail. The model must adapt without retraining.
The results were stunning. Even with only 25% of channels during training, CPiRi’s prediction accuracy dropped by only about 2% compared to full training. On PEMS-08, CPiRi with channel shuffling scored 10.72% WAPE when trained on 25% of channels. The baseline without shuffling scored 14.22%. That gap proves that channel shuffling is not just a training trick. It is the key to learning transferable channel relationships.
The model learned a “meta-skill” for understanding channel dynamics. Given any set of channel time series, it automatically infers the underlying spatial structure. It does not need to know which sensor is where. It learns the relationships from the data itself. This is exactly what industrial systems need.
Scalability: From Hundreds to Thousands of Channels
Real-world systems do not have dozens of channels. They have thousands. A large traffic monitoring system might have 8,600 sensors. A power grid could have even more. Most existing models struggle at this scale.
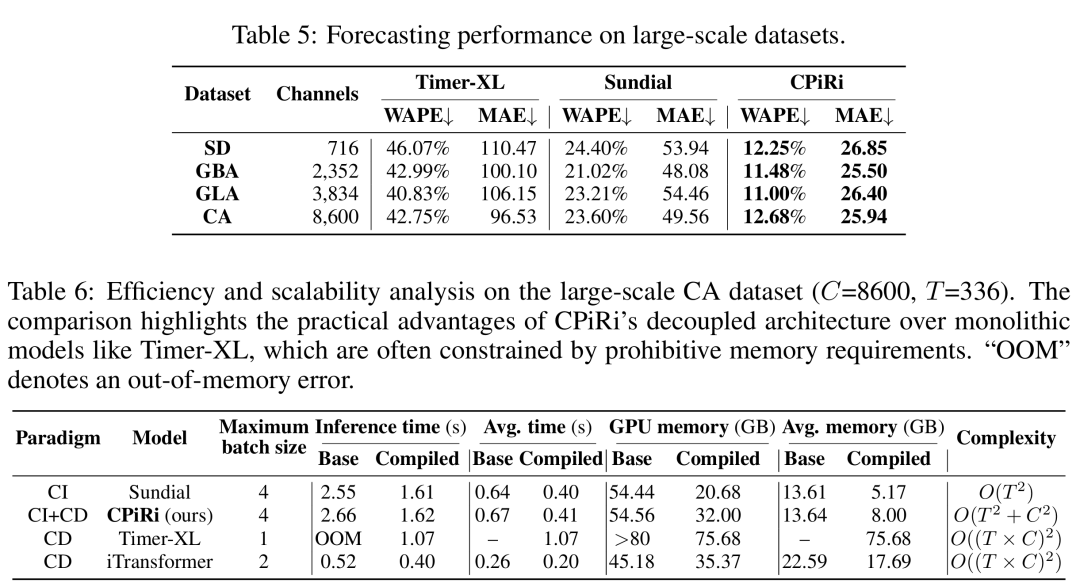
CPiRi was tested on a large-scale traffic dataset from California with 8,600 channels. The model maintained its accuracy while keeping computational costs reasonable. The linear complexity of the spatial interaction module means CPiRi scales to thousands of channels without exploding memory usage.
What the Model Actually Learns: A Visual Tour
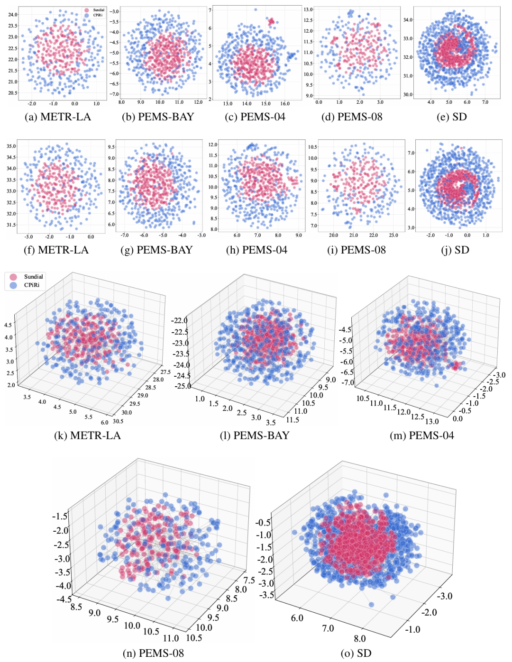
To understand what CPiRi learns, the team used UMAP to visualize the channel representations. UMAP is a technique that projects high-dimensional data into 2D or 3D space while preserving relationships.
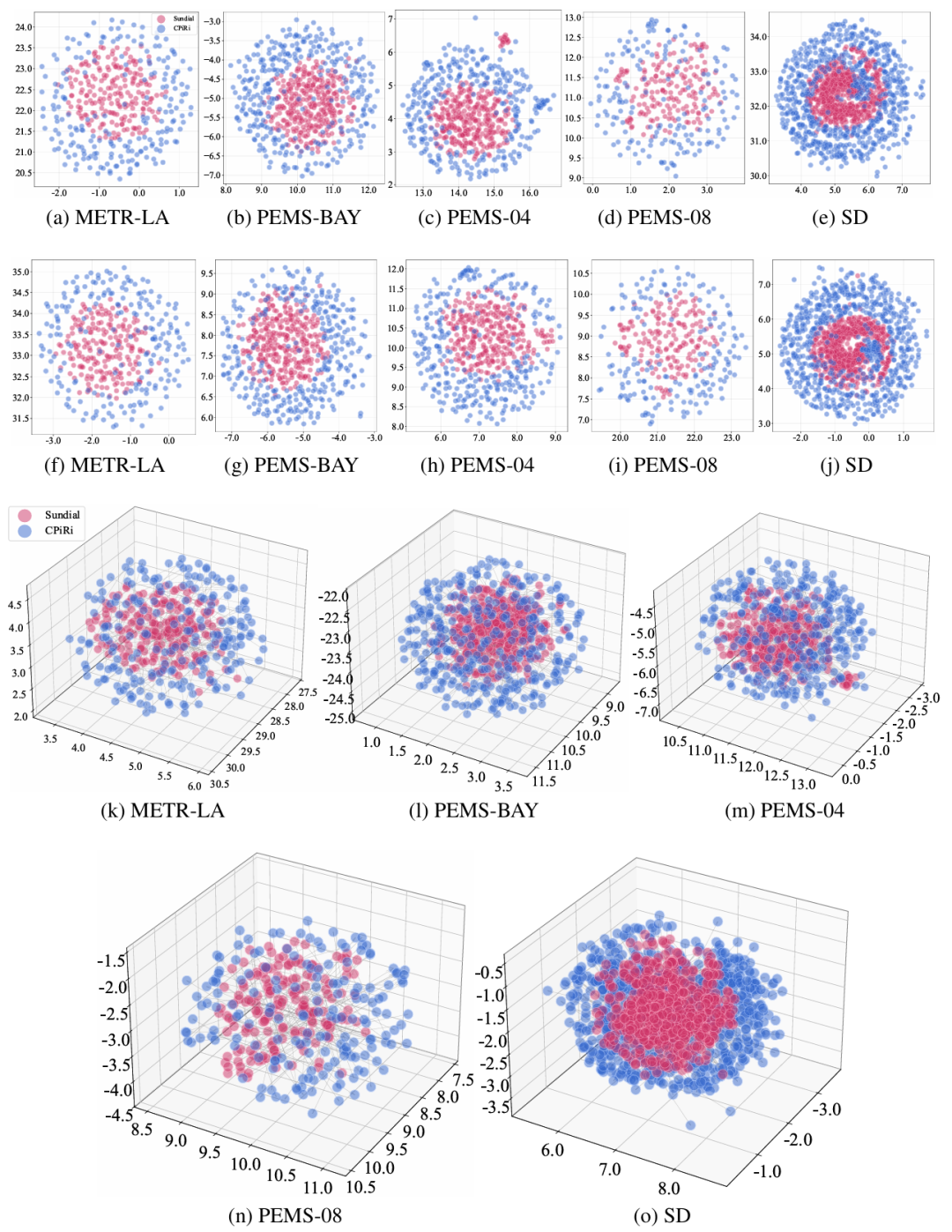
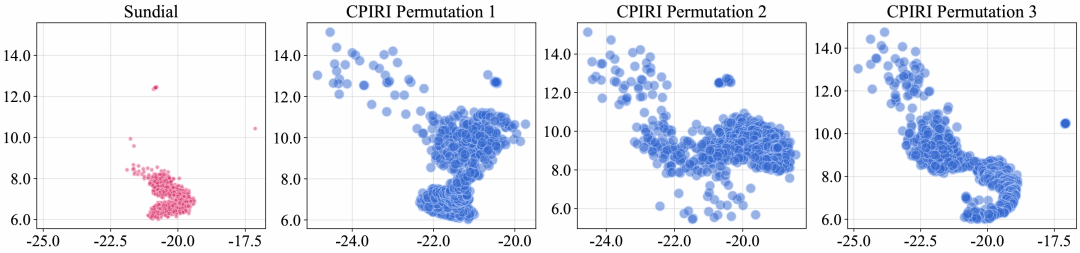
The visualizations revealed something beautiful. When channels had completely different temporal patterns, CPiRi’s spatial interaction module still organized them into a coherent global structure. The UMAP plots showed clear clusters of related channels. Even when channel order was shuffled, the clusters remained stable. This is visual proof that CPiRi learns true channel relationships, not positional artifacts.
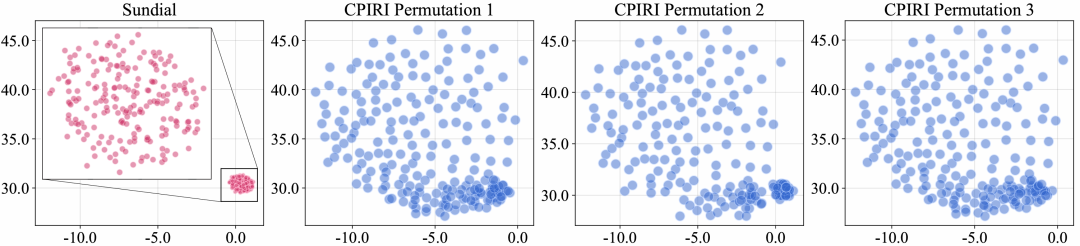
Conversely, the team showed what happens when a model overfits to one dataset. A model trained on a single dataset with fixed channel order showed “representation collapse” in UMAP. All channel representations clustered into a tight ball. The model had memorized the training data but lost the ability to generalize. This is exactly what happens to CD models when they encounter new channel configurations.
The Future of Dynamic MTSF
CPiRi represents a significant step forward for multivariate time series forecasting. It bridges the gap between academic research and industrial practice. In academia, the CI versus CD debate has been a theoretical puzzle. In industry, it is a practical nightmare.
Real systems are messy. Sensors get added, removed, and relocated. Traffic patterns change. Power grids expand. The spatial structure of the system evolves over time. Models that depend on fixed channel positions become useless the moment the system changes. Models that ignore channel relationships miss valuable information.
CPiRi offers a third path. It learns channel relationships in a way that is independent of channel order. It generalizes to new channel configurations without retraining. It scales to thousands of channels. And it achieves state-of-the-art accuracy while using only a fraction of the training data.
The key innovation is the combination of three ideas. Pre-trained temporal feature extraction provides stable, high-quality temporal representations. Permutation-invariant spatial interaction learns robust cross-channel relationships. Channel shuffling during training forces the model to develop meta-skills that transfer to new configurations.
For practitioners, CPiRi means that deploying a forecasting model no longer requires months of data collection and careful sensor mapping. You can train on a subset of channels and deploy across the full system. You can add new sensors without retraining. You can handle sensor failures gracefully. The model adapts to your system, not the other way around.
For researchers, CPiRi opens new directions. The paper shows that permutation invariance is not just a nice property. It is a fundamental requirement for robust multivariate forecasting. Future models will likely build on this insight, developing even stronger forms of position-independent learning.
The ICLR 2026 acceptance of CPiRi signals a shift in the field. The old CI versus CD debate is over. The winner is neither side. It is a new approach that transcends the binary choice. CPiRi proves that you can have the best of both worlds. You can model channel relationships without depending on channel order. You can achieve CD-level accuracy with CI-level stability.
In the world of time series forecasting, that is a revolution.