A research team from Tsinghua University has launched the Dolphin model, and it is making serious waves in the AI world. This tiny but powerful system uses only 6 million parameters, yet it delivers six times faster processing speed than the best existing models. By combining discrete visual tokens with a global-local attention design, Dolphin achieves state-of-the-art accuracy on multiple benchmark datasets. It also opens the door for high-quality speech separation to run directly on phones and edge devices, something that was impossible before.
Audio-visual speech separation, or AVSS for short, is the technology that helps computers understand who is speaking in noisy environments. It uses both sound and video to separate different voices when multiple people talk at once. This is essential for video calls, hearing aids, smart assistants, and any situation where clear communication matters in crowded spaces.
However, current AVSS systems face three major problems. First, they are too slow and consume too much power. Second, most models require massive pre-training on huge datasets and expensive high-end GPUs, making them impossible to run on everyday devices. Third, existing models focus too much on short-range audio details and miss the bigger picture, which causes delays and poor performance.
To solve these problems, the Tsinghua team led by Professor Kai Li developed Dolphin, a brand new efficient audio-visual speech separation model.
The model uses discrete visual tokens and a global-local attention mechanism to reduce computational complexity while breaking records on standard benchmark datasets.
Dolphin is the first AVSS model to push parameters below 6 million. Despite being extremely lightweight, it runs six times faster on GPU than current state-of-the-art models while maintaining the same or better accuracy.

Paper link: https://arxiv.org/pdf/2509.23610
Project page: https://cslikai.cn/Dolphin/
Code repository: https://github.com/JusperLee/Dolphin
Current AVSS methods face several important challenges.

Figure 1. Dolphin model overall pipeline diagram
To address these issues, Dolphin introduces a completely new technical framework with two key innovations.
DP-LipCoder: A lightweight dual-pathway discrete visual encoder
To better extract visual information before speech separation, the team designed a lightweight dual-pathway discrete visual encoder ai celebrity nudes called DP-LipCoder, shown in Figure 2.

Figure 2. DP-LipCoder module structure
This module uses a dual-pathway design with two separate routes. The content pathway captures speech-related data including lip movements and facial expressions. The style pathway handles style information through vector quantization. The system maps each video frame into discrete tokens using a pre-trained AV-HuBERT model. This forces the model to learn high-level semantic features rather than just raw pixel data. The discrete tokens allow Dolphin to extract visual information with extremely low computational cost. They also avoid the common problem where visual and audio information conflicts or overlaps.
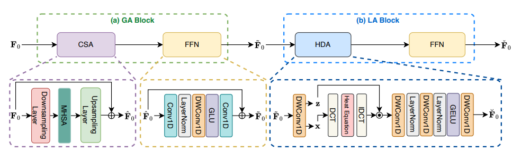
GLA Module: Global-local attention for long audio sequences
Dolphin replaces slow multi-head attention with a more efficient global-local attention mechanism called GLA, shown in Figure 3. This ensures the model can capture both overall context and fine local details during processing. The core design of the GLA module works as follows.

Figure 3. GLA module structure diagram
Direct target regression
Unlike existing methods that predict a mask between 0 and 1 and then multiply it with the mixed audio, which causes information loss, Dolphin directly regresses the target speech signal. Experimental results prove this approach is more efficient. It achieves about 0.5 dB improvement on the SI-SNRi metric.
Experimental Results and Performance Breakthrough
On standard benchmark datasets including LRS2, LRS3, and VoxCeleb2, Dolphin showed significant improvements over traditional methods. The results speak for themselves.


Summary and Future Impact
As AI models continue to grow larger, speech separation technology has followed the same trend. Bigger models usually mean better performance. But this makes it impossible to run on mobile devices and edge hardware. Dolphin breaks this pattern by proving that smaller models can achieve top performance through smart design.
By using discrete visual tokens and global-local attention, Dolphin demonstrates that lightweight models can fully match or even surpass larger models. This provides a completely new technical path for future hearing aids, phone apps, and real-time communication systems. It opens the door for high-quality speech separation to run on devices with limited resources.