Vision Transformers have become the backbone of modern computer vision. They power image classification, object detection, and segmentation tasks with strong results. However, the self-attention mechanism at the core of these models comes with a heavy cost. As image resolution grows, the computation needed for attention grows quadratically. This makes standard Vision Transformers too slow and power-hungry for mobile phones, tablets, and other devices with limited resources.
Researchers from Tsinghua University, Peking University, and industry labs have developed a new approach called CARE Transformer. This model rethinks how attention works by using a non-symmetric design that splits the attention process into two parts. One part handles local fine details. The other part captures global context. By running these two paths in parallel and sharing information between them, CARE Transformer achieves both high accuracy and fast speed on mobile hardware.
Tests on iPhone 13 and iPad Pro show that CARE Transformer delivers high accuracy while running in just over one millisecond per image. This proves that mobile vision Transformers no longer need to trade accuracy for speed.
Why Standard Vision Transformers Struggle on Mobile
Current efforts to build efficient Vision Transformers for mobile devices face two hard problems that are difficult to avoid.
First, most methods still use dense attention. They try to reduce the attention burden by limiting the receptive field or lowering the number of tokens. But this directly hurts the model’s ability to capture long-range relationships. The result is lower accuracy.
Second, some approaches use sparse attention. They optimize local attention blocks or combine them with global attention using complex hybrid designs. While these methods improve efficiency, they fail to fully unlock the potential of attention. They still suffer from the token reduction problem, which causes information loss and lower accuracy. In short, existing mobile-friendly approaches either sacrifice too much accuracy or remain too slow for real-time use.
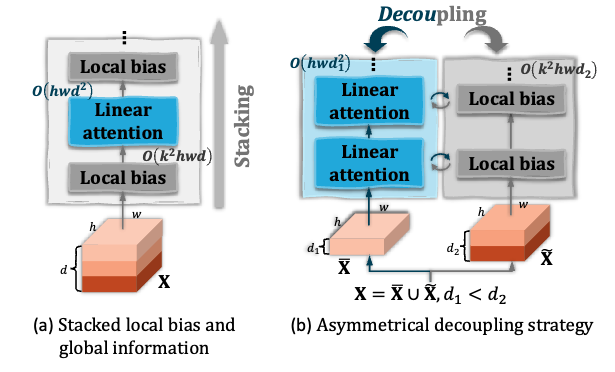
Figure 1 shows the key idea. Standard dense attention uses full pairwise computation across all spatial locations. The non-symmetric design in CARE Transformer splits this into two parallel paths. One path learns local detail through spatial offsets. The other path captures global context through channel-wise relationships. Both paths run at the same time and exchange information through cross-attention, giving the model the benefits of both local precision and global understanding.
How CARE Transformer Works
To solve the accuracy-speed trade-off, the research team took a different approach from traditional attention optimization. They introduced spatial offset and long-sequence learning as core elements of the design. The result is a non-symmetric dual-branch structure that serves as a new mobile vision Transformer backbone.

The paper is available at https://arxiv.org/pdf/2411.16170v2
The code is available at https://github.com/zhouyuan888888/CARE-Transformer
The framework uses non-symmetric attention as its core. The model processes information through two parallel non-symmetric branches at each dimension level. One branch performs local detail modeling. The other performs global context modeling. Each branch uses its own attention mechanism and learns through dimension-wise computation. This design effectively reduces the quadratic complexity of standard attention while keeping the model’s ability to capture both local and global information.
From a method perspective, CARE can be described simply. It breaks the dense attention burden of standard Vision Transformers into one core task. The model must handle local fine details and global context at the same time. The key insight is that these two types of information operate at different scales. By processing them through separate but connected paths, the model can organize computation more efficiently than running everything through a single dense attention layer.
 free ai porn maker
free ai porn maker
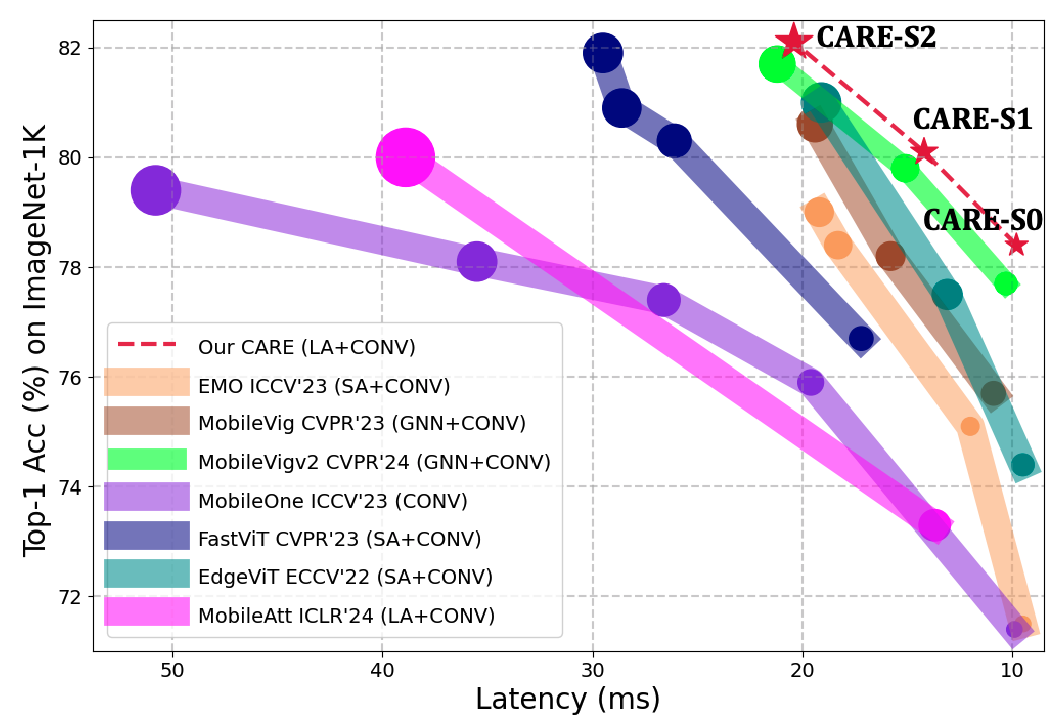
Figure 2 shows a visual comparison of accuracy versus latency and computational cost. In the chart, larger circles mean higher computational cost. SA stands for standard self-attention. LA stands for linear attention. GNN stands for graph neural network approaches. CARE sits in the favorable region of high accuracy and low latency.
Three Key Innovations
CARE Transformer makes breakthroughs in three areas that address the core problems holding back mobile Vision Transformers.
First, non-symmetric spatial offset and long-sequence learning. The model explores a new way to split the attention process. This directly answers clothes remover the core challenge of how to achieve efficient local detail modeling and global context capture at the same time.
Second, dual-branch non-symmetric attention. The model uses non-symmetric processing at each dimension level. It separates standard self-attention into local offset learning and global context learning modules. This breaks the computational bottleneck of traditional dense attention units while using non-symmetric communication to further compress attention computation across dimensions. This approach keeps local and global key context information while improving both attention efficiency and modeling accuracy.
Third, dynamic shift dual-branch fusion. The model uses a dual-branch fusion design with dynamic shift units. This releases the potential conflict between free ai nsfw local detail and global context values. The dynamic shift units allow the model to adjust how much it relies on each branch based on the input.
Through these units, the model can dynamically extract key context information across the full process. It achieves cross-level information exchange and context-aware information flow. The simple dual-branch fusion combines complementary information from both branches inside each basic unit. At each level, the model fuses local and global information through dynamic dual-branch fusion. This reduces computational overhead while ensuring that the model maintains strong representation ability.
The key value of this design is that CARE does not stop at simply splitting the model. Instead, it uses a unified formal approach to release the complementarity between different information sources.
In other words, CARE is not just a simple combination of plug-in modules. It is a new type of attention-model synergy that achieves true integration.
Test Results on Real Hardware
The research team ran large-scale experiments on ImageNet-1K, ADE20K, and COCO datasets. The results prove the method’s effectiveness. The model shows strong generalization across different tasks.
For example, on ImageNet-1K, the model achieves 78.4 percent and 82.1 percent Top-1 accuracy with latency of just 1.1 and 2.0 milliseconds on iPhone 13. On iPad Pro, latency drops to 0.8 and 1.5 milliseconds at the same accuracy levels.
CARE Transformer breaks the long-standing dilemma for mobile vision models. It does not force a choice between full global modeling, high accuracy, and high efficiency. As long as the model can organize local detail, global context, and their complementary relationship well, attention can still achieve strong performance while releasing the potential for high efficiency.
What Comes Next
The research team states that future work will focus on two directions.
First, they will optimize the CARE Transformer architecture and framework. They plan to use neural architecture search to explore the optimal structural design for CARE-like frameworks. This could uncover more powerful accuracy-efficiency trade-offs.
Second, they will extend CARE to more vision tasks. They will test the method on video understanding models and multimodal models to verify its general effectiveness across different model types.
Final Thoughts
CARE Transformer offers a new path for mobile AI. It proves that vision models can run fast on phones and tablets without losing accuracy. The non-symmetric dual-branch design is a fresh way to think about attention. Instead of trying to make dense attention cheaper, CARE splits the problem into two simpler paths that work together.
For developers building mobile apps with computer vision, this means better performance without bigger models. For researchers, it shows that there is still room to improve how Transformers work at the fundamental level. The code is open source, so teams can start testing CARE Transformer in their own projects today.