Claude just helped crack open the Apple Neural Engine. What was hidden inside the M4 chip is now exposed. For the first time, developers can train AI models directly on the Neural Processing Unit hentai ai chat inside every Mac mini. The age of AI training on consumer devices has arrived.
Engineer Manjeet Singh used Claude to reverse engineer the Apple Neural Engine. He trained a Transformer model on the NPU. Not the GPU. Not the CPU. The dedicated AI chip that Apple never intended for training. The results are shocking.
free ai nsfw
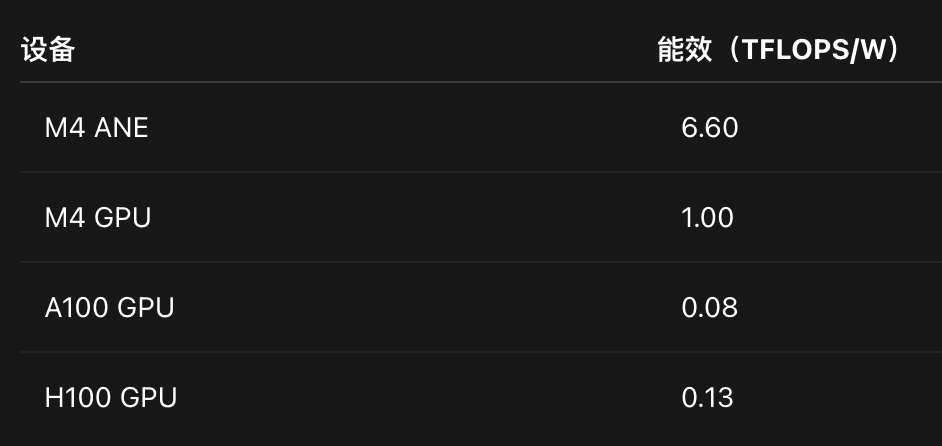
A ai nude generator free single Transformer layer with 768 dimensions and 512 sequence length runs in 9.3 milliseconds. The energy efficiency reaches 6.6 TFLOPS per watt. That beats an A100 by 80 percent and an H100 by 50 percent. Yes, a Mac mini is outperforming data center chips on efficiency.

Manjeet Singh described Claude as the perfect collaborator. One person acts as the system architect. The other acts as the implementation engineer. In this case, Claude was both. The project is open source and available on GitHub.
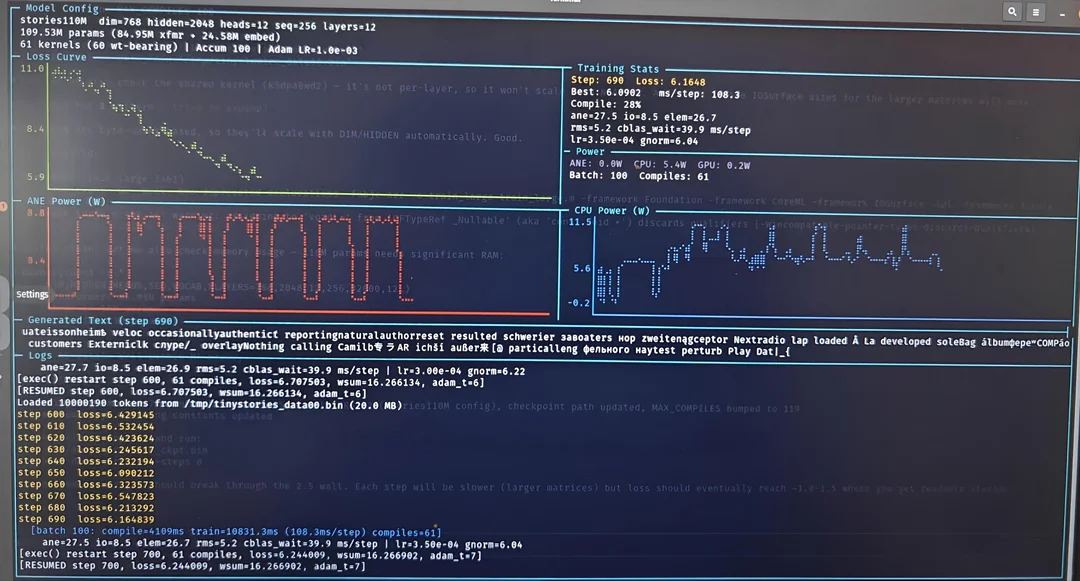
Claude played several key roles. It reverse engineered the MIL graph format. It decoded the E5 instruction set. It designed the CoreML workaround. And it directly manipulated the ANE hardware to implement forward and backward propagation.
The breakthrough means anyone with a Mac can now train AI models at home. No cloud subscription. No expensive GPU cluster. Just a small desktop computer and the Neural Engine that Apple put inside every recent Mac, iPhone, and iPad.
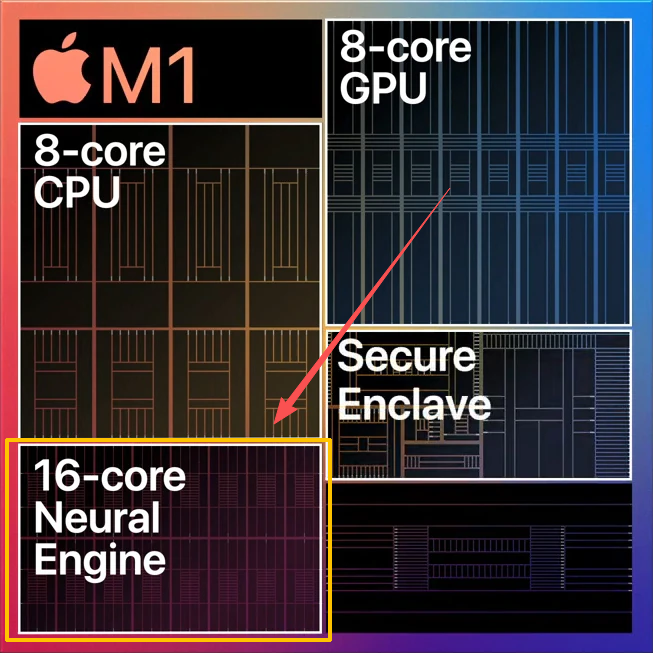
So what exactly is the Apple Neural Engine? Every new iPhone, iPad, and Mac comes equipped with this dedicated AI processor. It is a Neural Processing Unit designed specifically for machine learning tasks.
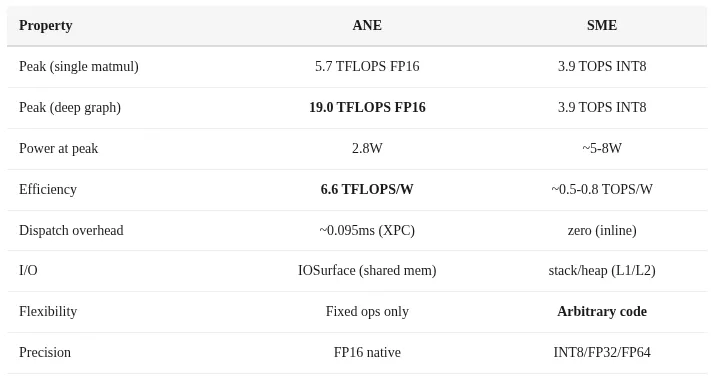
Unlike a GPU which renders graphics, the NPU focuses entirely on matrix math. It is a fixed-function accelerator built for multiply-accumulate operations. Once data is loaded, the chip processes it in a continuous pipeline without fetching new instructions. This makes it incredibly efficient for inference.
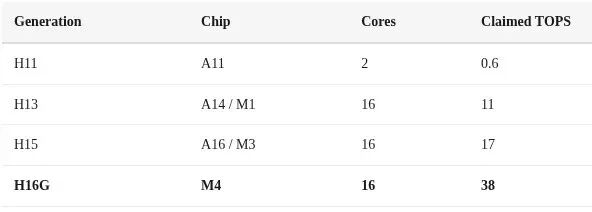
The M4 chip’s Neural Engine is called ANE H16G. It has 16 cores and supports 127 TOPS of INT8 operations. It includes DVFS dynamic voltage and frequency scaling. Most impressively, it has power control precise enough to reach exactly zero watts when idle.
Apple has always kept the Neural Engine locked behind CoreML. This framework only supports inference, not training. CoreML compiles models into a format the ANE can run, but it never exposes the hardware directly. Manjeet Singh proved this lock can be picked.
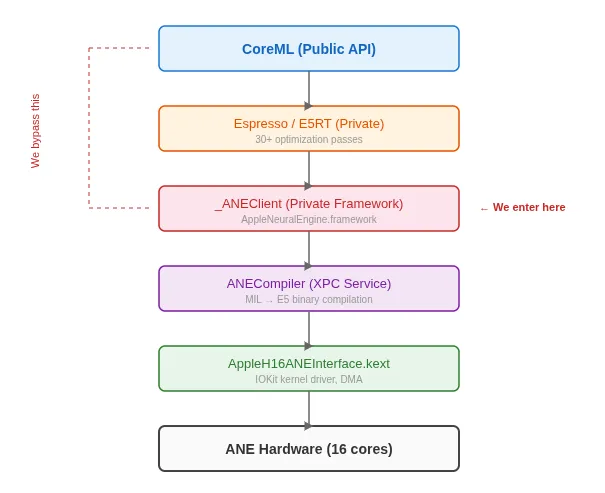
The key discovery is that CoreML is not the only gateway. Inside the AppleNeuralEngine framework, a private class called ANEClient provides direct access to the hardware. CoreML is just a wrapper on top of this lower layer. Singh used this private API to send training commands directly to the NPU.

The test project ran on a Mac mini M4. It trained a 1.1 billion parameter micro-GPT model. This is not a toy example. It is a real language model that can generate text. The training pipeline used the NPU for forward passes and backward propagation, the two essential steps for learning.
Currently, the chip cannot train the largest models alone. But through clustering or using LoRA fine-tuning, even consumer devices can handle 30 billion or 70 billion parameter models. The barrier to AI training has never been lower.
Why train on the NPU instead of the GPU? The answer is efficiency. The ANE achieves 6.6 TFLOPS per watt at 2.8 watts. By comparison, Metal GPU on the same chip reaches only 1 TFLOPS per watt. The H100 reaches 1.4 TFLOPS per watt. The Mac mini’s tiny AI chip is crushing data center hardware on energy efficiency.
But there is a catch. The 38 TOPS number that Apple advertises is misleading. TOPS stands for Tera Operations Per Second. It counts every multiply-accumulate as two operations. The formula is number of MAC units times MAC frequency times 2. This is a marketing number, not a real-world performance metric.
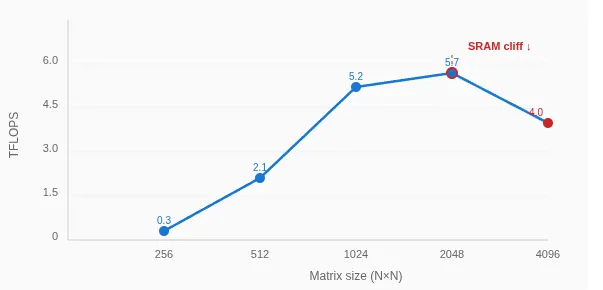
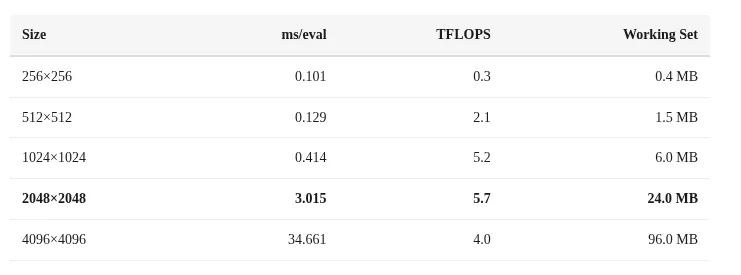
The real limitation is memory. The ANE chip has only 32 megabytes of SRAM. For matrix multiplication, this creates a severe bottleneck. When matrices exceed the SRAM capacity, performance drops dramatically. This is the memory wall that all AI chips face.
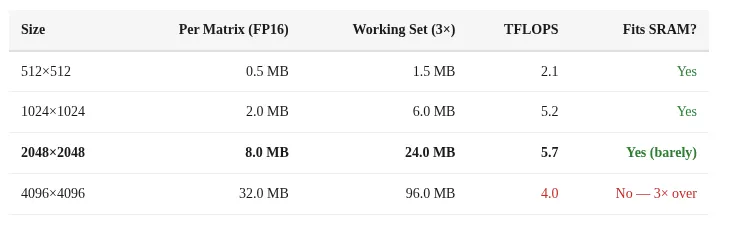
For FP16 operations, the performance gap between 24MB and 96MB matrix sizes reveals the SRAM limit. The ANE chip has approximately 32MB of SRAM. When data exceeds this, the chip must fetch from slower memory, and performance collapses.

Apple’s documentation never explicitly confirms this, but the ANE appears to use a fixed tag-based storage system. Matrix multiplication is converted into a 1 by 1 convolution format. This is different from how GPUs handle matrix math, but the ANE’s data path is designed for high-efficiency convolution.
The hardware is designed for inference, not training. All 16 cores are busy processing fixed weights. The more data you add, the closer you get to the memory bandwidth limit. This is why CoreML fails for training. It was never designed for it.
But Singh found a way around this. By using the private ANEClient API, he bypassed CoreML entirely. The chip can do more than Apple admits. The limitation was software, not hardware.
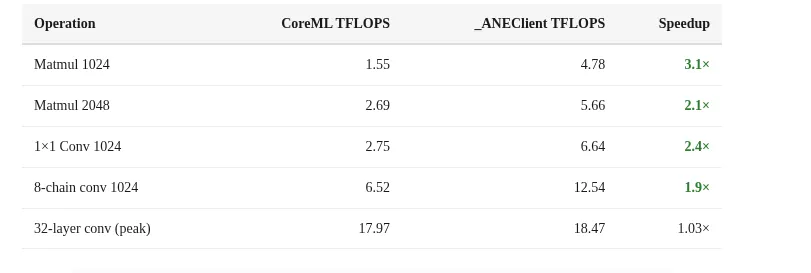
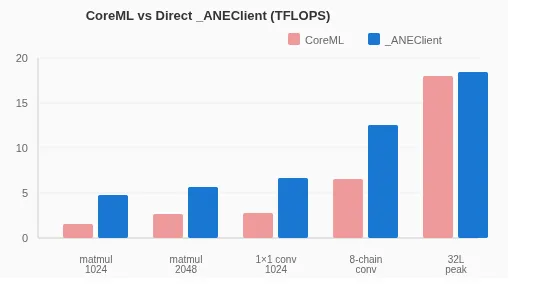
For small matrices, CoreML can achieve 2 to 4 times speedup. But under training workloads, the ANE is only slightly faster than the CPU, sometimes slower. This is because token generation and real-time inference have different characteristics. CoreML was optimized for inference, not learning.
Apple advertises 38 TOPS for the M4 Neural Engine. But this number needs careful decoding. For FP16 and INT8 operations, the performance differs significantly. INT8 is about 2 times faster than FP16. But INT8 does not save memory bandwidth because Apple converts INT8 weights to FP16 before execution.
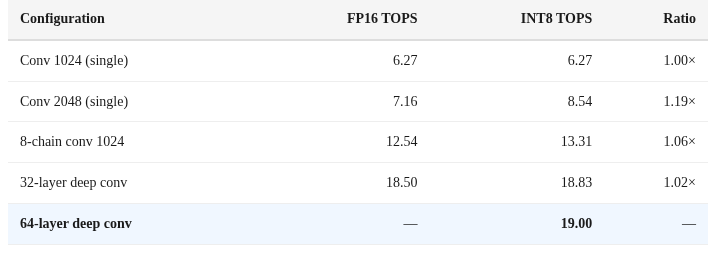
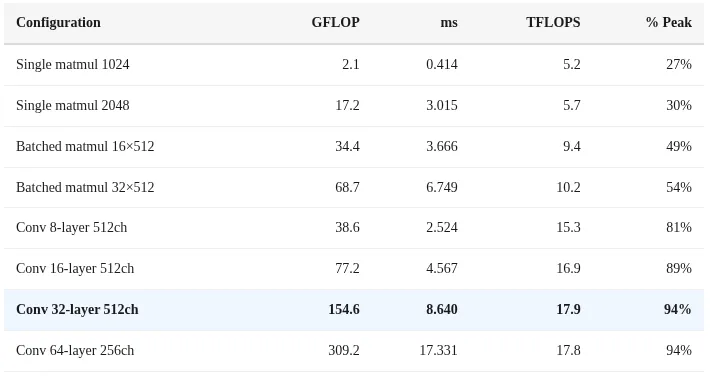
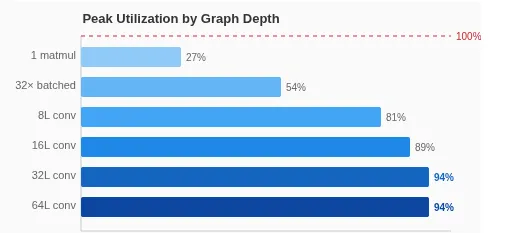
The real FP16 performance is approximately 19 TFLOPS. Using the roofline model, the peak compute is about 1.2 TFLOPS per watt for 16 cores. At 32 cores, the utilization reaches 94 percent. This means the hardware is being used almost perfectly. Only a custom GPU kernel could do better.
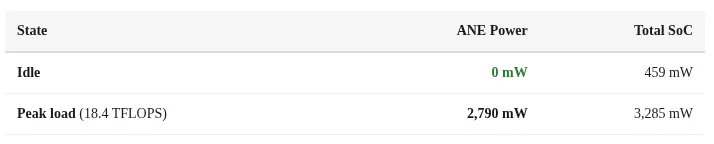

The real magic of the ANE is its power management. The hardware power control can shut down power completely when idle. There is no leakage. No waste. At 2.8 watts, it achieves 6.6 TFLOPS per watt. This is why Apple Silicon has been winning on efficiency.
What does this mean for the future? It means AI training is no longer locked in data centers. A Mac mini can now do what previously required thousands of dollars of cloud credits. Students can experiment. Small teams can innovate. Independent researchers can compete.
The M4 CPU also brings SME extensions, Scalable Matrix Extensions, which complement the ANE. Singh’s training pipeline uses the ANE for the heavy matrix math and the CPU SME for token generation and other tasks. The combination is elegant.
Apple has not officially acknowledged this capability. The company positions the Neural Engine for inference only. But the hardware is clearly capable of more. The limitation was always software, not silicon.
Claude helped prove that. By working through the reverse engineering process, Claude and Singh showed that consumer AI chips have been massively undervalued. The M4 is not just for running pre-trained models. It can create them.

For Apple, this is both a threat and an opportunity. If developers start using the Neural Engine for training, Apple may need to open up the API officially. CoreML could evolve from an inference framework into a full training platform. The Mac could become the default machine for AI education and experimentation.
For Nvidia, this is a warning. The data center monopoly on AI training is cracking. Consumer chips are catching up. Not in raw power, but in efficiency and accessibility. When a Mac mini can train a billion-parameter model at home, the economics of cloud AI change.
The project is open source. The code is public. Anyone can replicate it. That is the point. AI training belongs to everyone, not just tech giants with server farms. Claude and a determined engineer just proved it.