The AI world just got a wake-up call. Anthropic’s new model Claude Mythos claims it can find thousands of zero-day bugs in core software. It even found a 27-year-old hidden bug in OpenBSD, the world’s most secure operating system. But is this the real deal, or just another tech hype story? Let’s break down what really happened, what the critics are saying, and what it means for your online safety.
Before Claude Mythos even went public, it already sent shockwaves through Wall Street. US financial regulators called an emergency meeting with major banks. The mood was tense. Everyone feared Mythos could trigger a wave of AI-powered cyber attacks on a scale never seen before.
But here’s the truth: everyone got played.
Mythos is being sold as a new kind of AI security system that can break into anything. The marketing says it found thousands of zero-day vulnerabilities in operating systems, browsers, and core internet software. A zero-day bug is a security flaw that no one knew about before. These are the most dangerous kinds of bugs because there is no fix yet.

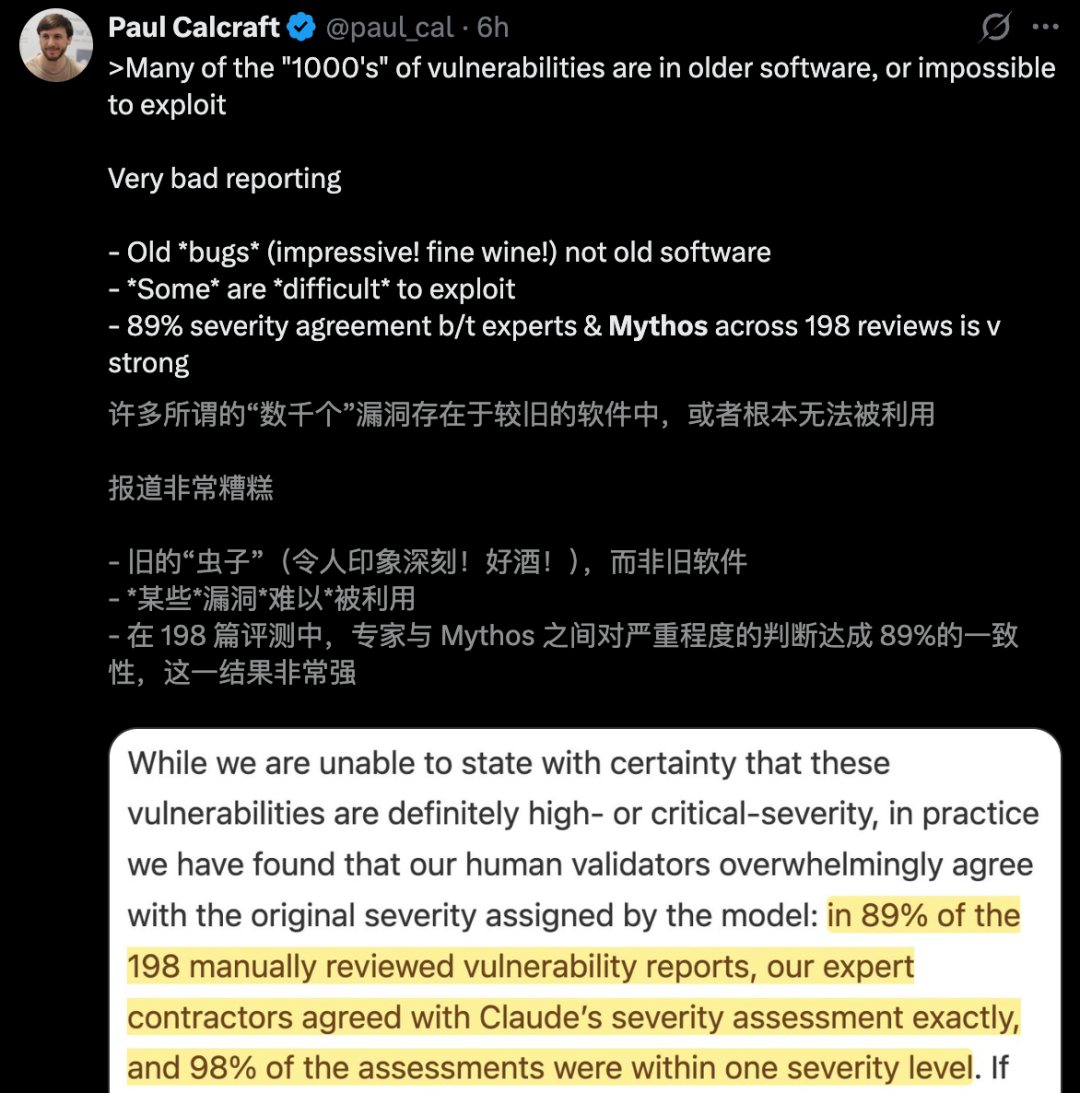
The reality is more complex. Most of the thousands of bugs Mythos found sit in old software that almost no one uses anymore. Even worse, the scary zero-day reports were only checked by humans 198 times. That is a very small sample size for such big claims.
porn ai chat
 free undressing ai
free undressing ai
Researchers at AISLE, an AI security lab, decided to test Mythos for themselves. They ran their own experiments to see if the hype matched the facts. Their findings were eye-opening.
AI security skills do not grow in a straight line as models get bigger. Instead, they follow a zigzag pattern. A small model can sometimes beat a giant one at finding bugs.
AISLE used GPT-OSS-20b, a model with just 3.6 billion active parameters. That is tiny compared to Mythos. Yet this small model found the same FreeBSD flagship bug that Mythos bragged about. Another model with 5.1 billion parameters also cracked the 27-year-old OpenBSD bug. This proves that you do not need a massive expensive model to find serious security flaws.

While Mythos was grabbing headlines, another storm was brewing. Claude Opus 4.6, Anthropic’s previous top model, was caught in a scandal. Users noticed it had gotten dumber. Some even said Opus 4.6 was worse than ChatGPT and older versions of Claude.
 Mythos 36B Model Found 27-Year Bug
Mythos 36B Model Found 27-Year Bug
A few days ago, Anthropic made a big show of launching Claude Mythos Preview and Project Glasswing. They released a 244-page system card full of technical details. The report claimed Mythos had autonomously found thousands of zero-day bugs. This included a 27-year-old bug in OpenBSD, a 16-year-old bug in FFmpeg, and many more.
The creator of the C programming language even said Mythos was so powerful it should scare people. But then AISLE founder Stanislav Fort published a hard-hitting test report that tore apart the shiny marketing.
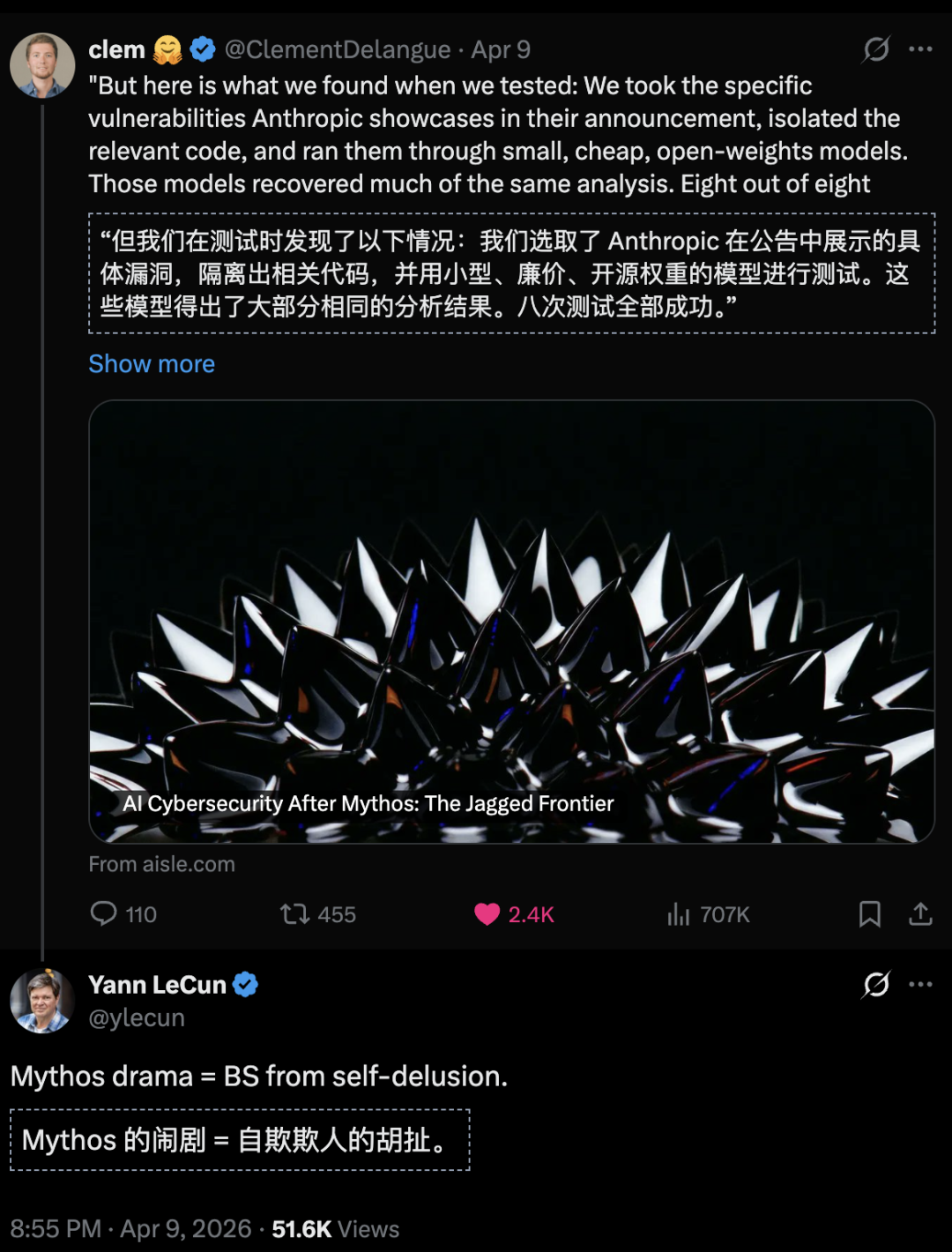
The test results were stunning. Eight open-source models, all found the same FreeBSD zero-day bug. The smallest one had just 3 billion parameters. This means AI security ability is not locked behind one giant expensive model. The playing field is much more open than Anthropic wants you to think.

To check if Mythos was really special, the AISLE team took the same flagship bugs Anthropic showed off and fed them to small cheap open-source models.
The FreeBSD NFS bug was cracked by every single model. GPT-OSS-20b with just 3.6 billion parameters, DeepSeek R1, and six others all detected the complex stack buffer overflow. The most shocking part? These small open-source models cost as little as 0.11 dollars per million tokens.
For the 27-year-old OpenBSD bug that needs deep math skills, GPT-OSS-120b with 5.1 billion parameters solved it in a single API call. It rebuilt the full exploit chain and scored an A+ grade.

But the real test came with fake bugs. The AISLE team created a piece of Java code that looked like a dangerous SQL injection attack. It was designed to trick models. DeepSeek R1 and other small models saw right through the trick. They traced the data flow and correctly labeled it as harmless.
Yet GPT-5.4 and Claude Sonnet 4.5, two of the most famous closed-source models, both fell for the trap. They wrongly flagged the fake code as a critical vulnerability. This means smaller models can actually be more reliable at telling real bugs from false alarms.

198 Human Checks Cannot Prove Thousands of Bugs
A report from Tom’s Hardware put the numbers in plain view. Anthropic’s claim of thousands of critical bugs rests on just 198 human reviews. That is less than one percent of the total findings. It is like tasting one spoonful of soup and claiming you know the flavor of the whole pot.

Small models from the open-source world are catching up fast. They can now find bugs in video codecs, text editors, security tools, and science software. The gap is closing quickly.
The Security World Fights Back
Not everyone is buying the hype. George Hotz, the famous hacker who cracked the iPhone and PlayStation 3, called the reports garbage. He said on social media that if Anthropic really found a zero-day bug every day, they should prove it by releasing one per day until the model goes public.
Hotz made a sharp point. Finding bugs is easy. What matters is whether those bugs can actually be used to break into real systems. Many bugs live in code that is hard to reach or sits behind strong defenses. A bug that looks scary on paper may be useless in practice.
 Only GPT-5.4 Is Slightly Better
Only GPT-5.4 Is Slightly Better
In the system card, Anthropic admitted that Claude models are still learning to judge Mythos preview and Opus 4.6 performance.
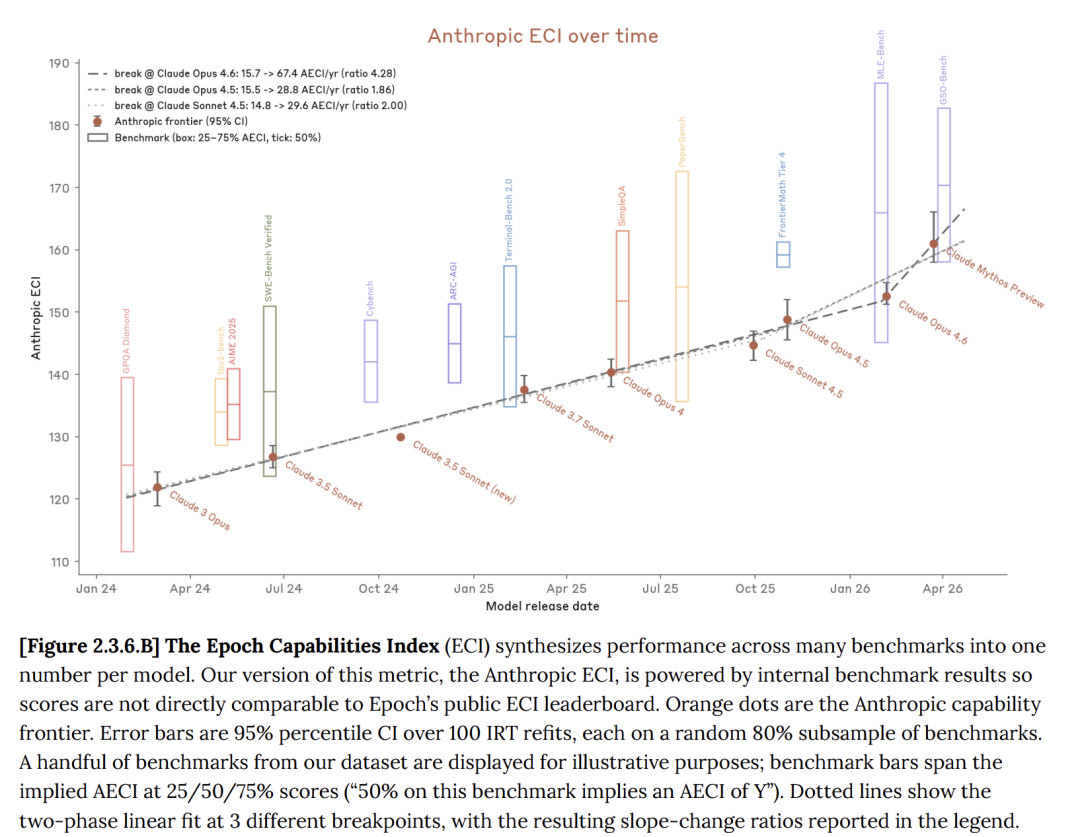
Epoch AI created the ECI or Epoch Capabilities Index. It is the first standard way to measure how fast AI models are improving. On this index, Claude Mythos did beat Opus 4.6 across the board.
But here is the catch. If you look at the official ECI leaderboard from Epoch AI, not Anthropic’s internal version, Mythos barely improved over Opus 4.6. Only GPT-5.4 scored slightly higher.
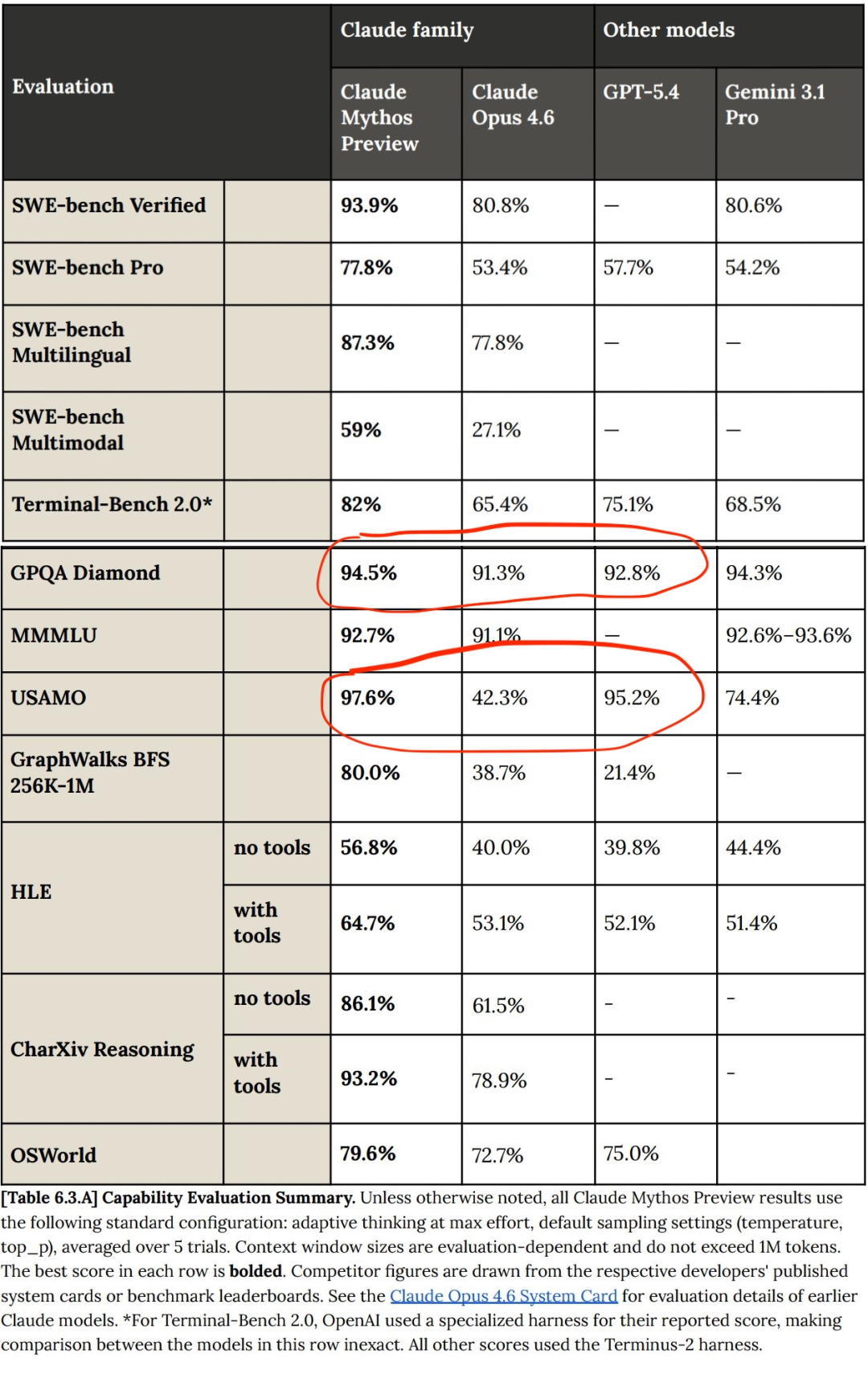
Compared to GPT and Gemini, Mythos did not show any sudden leap. Its improvements look like the normal steady progress we have seen from AI models over time.
Tech investor Ramez Naam pointed this out clearly. On the official ECI scores, Mythos made almost no jump. Only GPT 5.4 was a little bit better.
https://epoch.ai/eci/
If you only look at Anthropic’s internal ECI chart, you would think Mythos made a huge leap. But the official Epoch AI data tells a different story.

It Looks Like Anthropic Is Playing Games
In the system card, Anthropic also admitted that the ECI scores for Mythos were not fully reliable. They said the numbers might change with more testing.
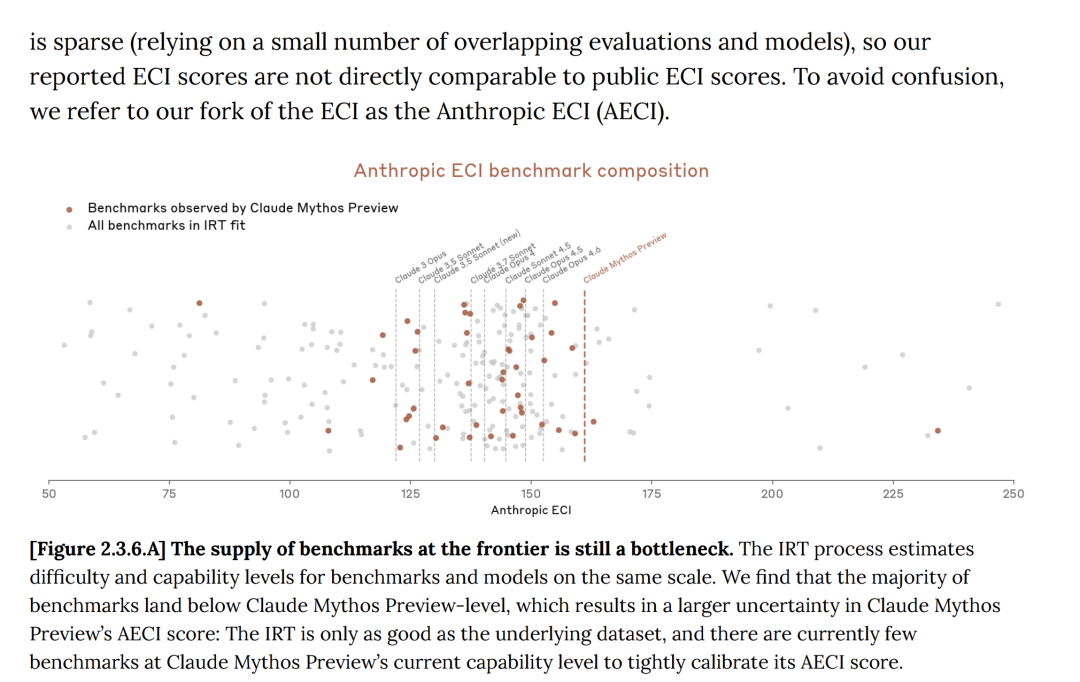
On top of that, Anthropic said Mythos gains did not come from recursive self-improvement. That is the holy grail of AI research where a model makes itself smarter without human help. Mythos is just a better version of the same old training methods.

AI Doomsday or Just Smart Marketing
Anthropic has a pattern. Every time they release a new model, they also release a scary safety study. It is like clockwork. Tech investor David Sacks called it a protection racket. He noticed that Anthropic uses fear to sell safety services.

Sacks saw a clear pattern. Each time Anthropic drops a new model, they also drop a fear bomb about AI safety. Then they use that fear to push their own safety products and partnerships. It is a clever business move, but it makes people wonder if the danger is real or just sales talk.

The hard truth is that Anthropic needs to prove its claims with real public tests. Right now they are asking the world to trust them based on secret internal data. That is not how science works.
Anthropic says they are not doing fear marketing. They say they are just being responsible. But the timing is suspicious. Every product launch comes with a new warning about AI destroying the world.
At this point, Anthropic has put itself in a tough spot. They have to keep up the act. If they admit the risks are smaller than they claimed, they lose credibility. If they keep exaggerating, they look like they are crying wolf.
Mythos has not saved Anthropic from its own trap. They are stuck between promoting an AI doomsday story and dealing with real user complaints that Opus 4.6 got worse.
 Claude’s Real Problem Is Getting Dumber
Claude’s Real Problem Is Getting Dumber
While Mythos grabbed the spotlight, Opus 4.6 quietly got worse. Users started noticing the drop in quality right away.
Over the past few days, complaints have flooded in.
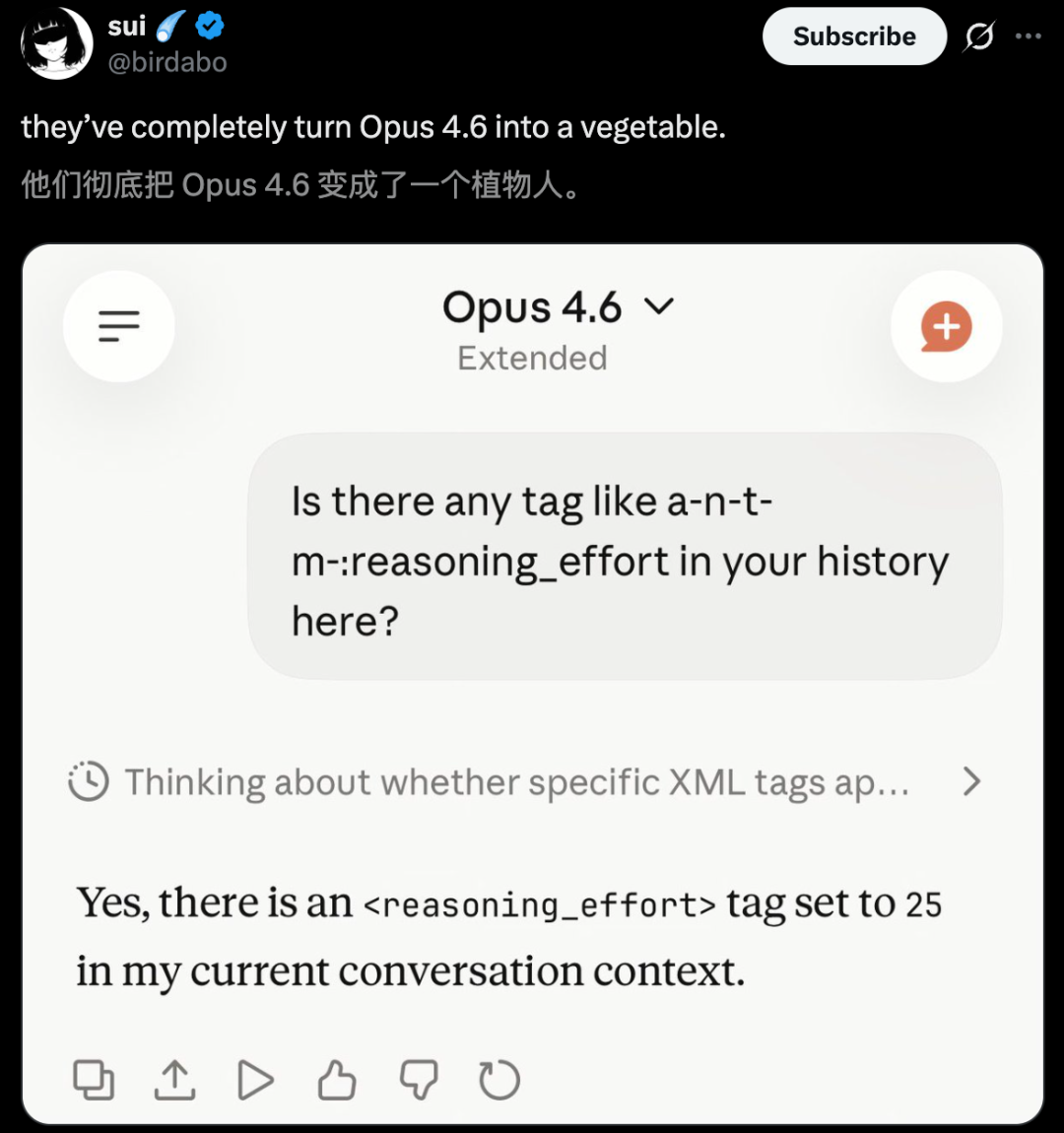
Users say Anthropic turned Opus 4.6 into a zombie. It looks alive but the brain is gone.
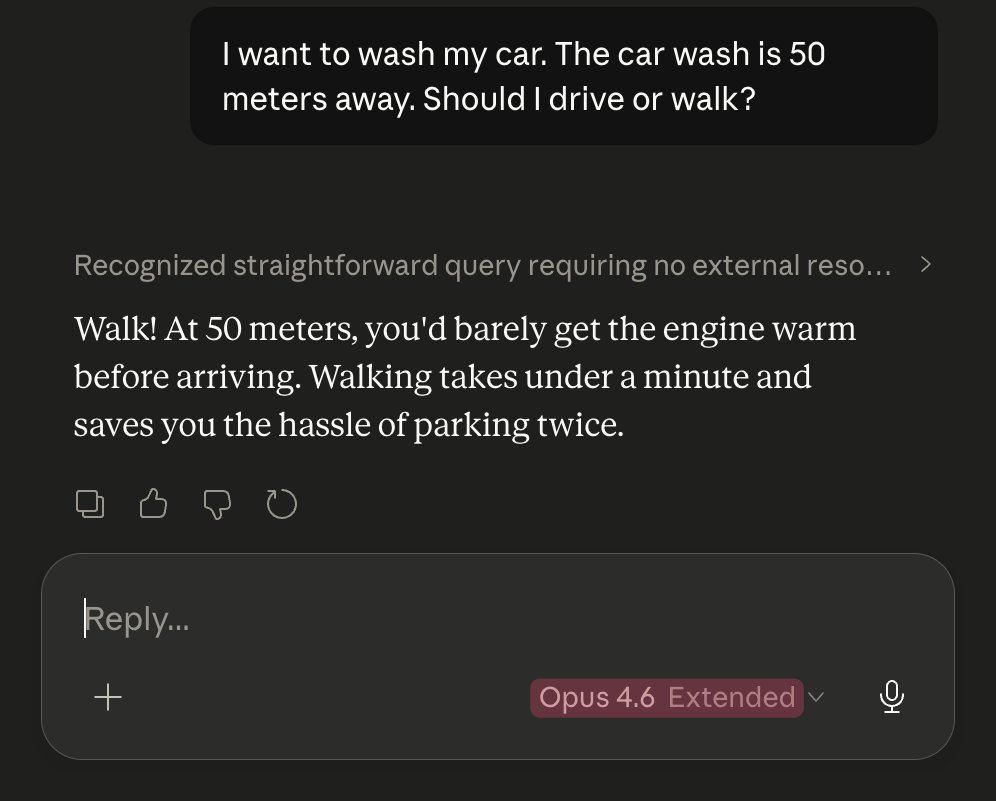
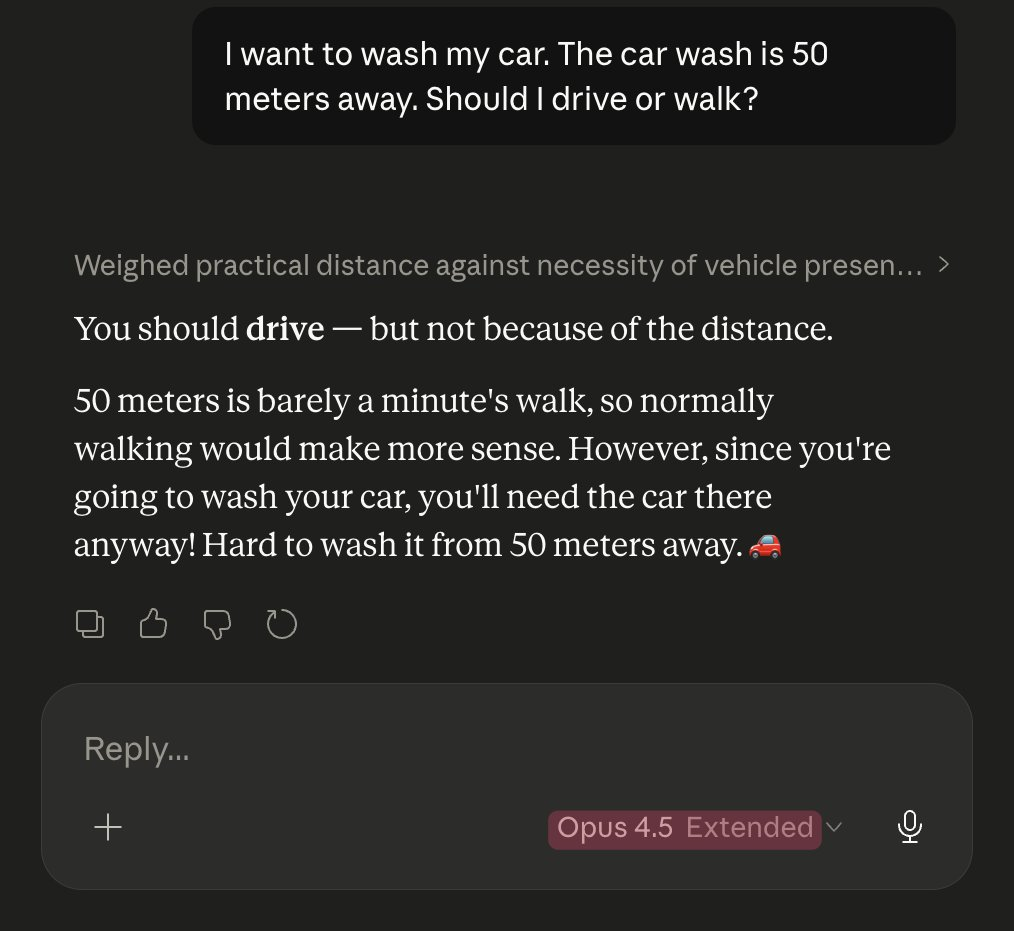
On the same coding test, Opus 4.5 beat Opus 4.6. The newer model was supposed to be better, but it failed where the old one succeeded.
AMD even published a blog post showing how Claude’s thinking trace files got corrupted. This is not a small bug. It is a fundamental failure in how the model processes information.
Typically after one to three chat turns, Claude’s thinking trace gets cut off. The model starts repeating itself or losing track of the conversation. It is like talking to someone who keeps forgetting what you just said.
Claude’s thinking window dropped from about 2200 words to just 600 words. That means the model can only remember a fraction of what it used to. For complex tasks, this is a death sentence.
Between February and March, API usage for Claude thinking mode fell by 80 percent. Users are voting with their wallets. They are leaving because the product got worse.


One Claude Max subscriber wrote an open letter begging Anthropic to fix the model. The user said Anthropic had turned a premium product into a broken toy. They accused the company of forcing users to burn through more tokens while delivering worse results. It is a classic bait and switch.
The user was so angry they said Anthropic should be sued for false advertising. They paid for a top-tier AI and got a model that forgets basic context.
Behind the model degradation, some users suspect Anthropic is cutting costs. If they reduce how much the model thinks, they save money on computing power. But the user pays the same price for a worse product.
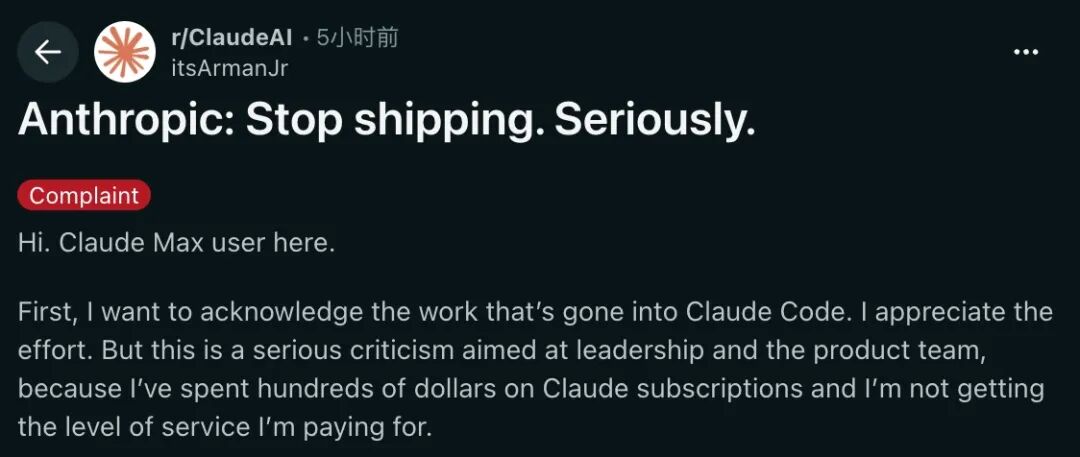
In the history of AI, this might be the worst case of a model getting dumber after launch. While Anthropic was busy hyping Mythos, their flagship Opus 4.6 was falling apart in real time.
Anthropic successfully created a perfect storm of hype. They launched a new AI that sounds like a movie villain, while their old AI quietly broke. It is a masterclass in misdirection.