The Problem: Why AI Models “Overthink” Everything
If you’ve ever watched an AI model like DeepSeek-R1 or OpenAI’s GPT Thinking work through a problem, you’ve probably noticed something strange. Even after finding the right answer, the model keeps going. It writes things like:
-
“Wait, let me double-check…”
-
“Alternatively, maybe I should consider…”
-
“Hmm, but what if…”
This is called “overthinking” in AI research. The model produces long chains of thought — sometimes thousands of tokens — filled with self-corrections, backtracking, and redundant reasoning. It’s like a student who writes a correct answer on a test, then keeps writing “just to be sure,” filling five extra pages with unnecessary work.
For AI companies running these models, this isn’t just annoying. It’s expensive. Every extra token costs compute power, electricity, and money. For users, it means longer wait times for answers. And here’s the frustrating part: most of this extra thinking doesn’t improve the answer. It’s just waste.
Why Existing Fixes Don’t Work?
The obvious solution seems simple: punish long responses during training. If the model gets a penalty for being too wordy, it should learn to be concise, right?
Researchers have tried this approach. It’s called “length penalty” in reinforcement learning training. But it has a fatal flaw that nobody fully understood until now.
When you punish the entire response for being long, you create a terrible trade-off:
-
Punish too hard → The model skips necessary thinking steps and gets answers wrong
-
Punish too soft → The model keeps overthinking and wasting tokens
It’s a lose-lose situation. You can either have a fast model that’s wrong, or a slow model that’s right. Getting both speed and accuracy seemed impossible.
The Breakthrough: What ICLR 2026 Oral Paper DECS Discovered
A research team from Fudan University, Shanghai Jiao Tong University, and Shanghai Artificial Intelligence Laboratory decided to solve this problem from the ground up. Their paper, accepted as an Oral presentation at ICLR 2026 (one of the top AI conferences in the world), reveals something nobody had systematically proven before.
They found that length penalty fails because of two hidden bugs in how AI models learn:
Bug #1: It Punishes the Wrong Tokens
When an AI model thinks through a problem, some tokens are essential exploration. Words like “wait,” “however,” and “alternatively” aren’t mistakes. They’re the model’s way of testing different paths to find the right answer. They’re like a detective following leads — some leads go nowhere, but you need to check them to solve the case.
Length penalty doesn’t understand this. It treats every token the same way. A “wait” that leads to a breakthrough gets the same punishment as a “let me reconsider” that adds nothing. Over time, the model learns to avoid exploration entirely. It stops checking alternative paths and settles for the first answer it finds — even if that answer is wrong.
This is especially bad when easy problems make up most of the training data. The model sees that short answers get rewarded on simple questions, so it applies the same shortcut thinking to hard questions where it actually needs to explore.
Bug #2: It Secretly Rewards Waste
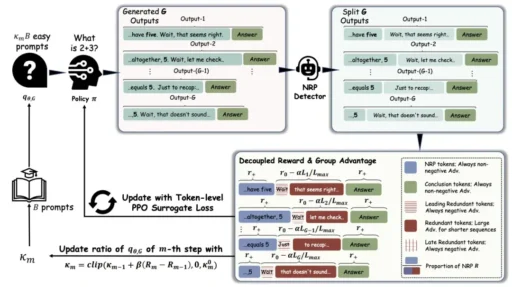
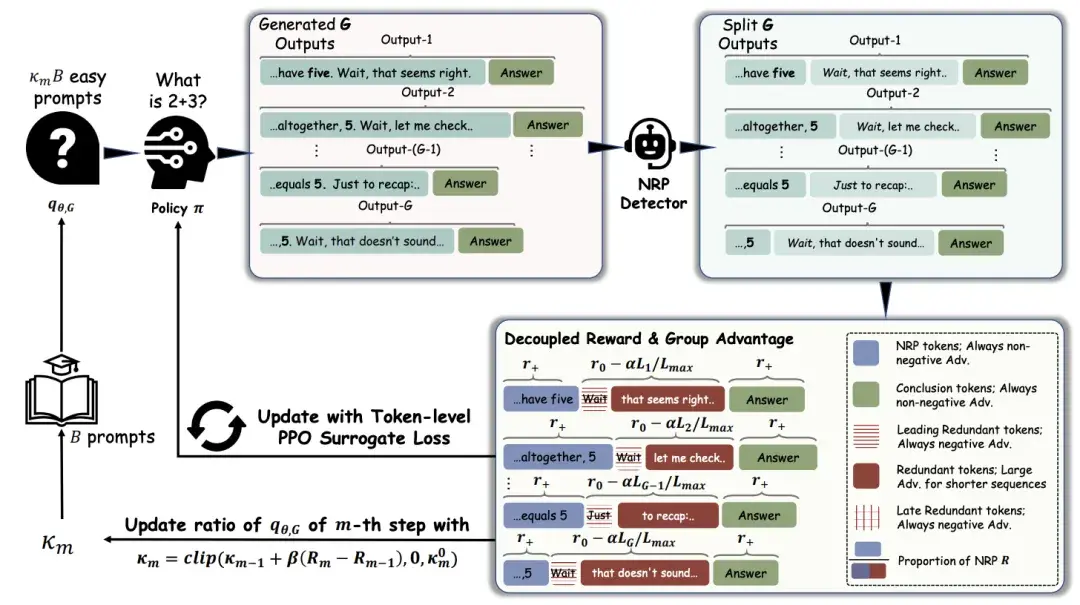
The researchers introduced a powerful new concept: the Necessary Reasoning Prefix (NRP).
Think of NRP as the shortest path from “start thinking” to “first correct answer.” Everything after that point is pure waste. If a model solves a math problem in 50 tokens but keeps writing for another 100 tokens, those 100 tokens are redundant.
Here’s the shocking discovery: Existing training methods sometimes reward these extra tokens.
How? In group-based training, if one model’s answer is shorter than others in the group, the whole answer gets a bonus — even if the shorter answer still contains 50 tokens of waste after the correct answer. The model learns “shorter is better” but never learns “stop when you’re done.”
It’s like giving a student extra credit for turning in a 5-page essay instead of a 10-page essay, even though both students wrote 2 pages of good content followed by 3 pages of filler. The shorter essay still has filler — it just has less of it.
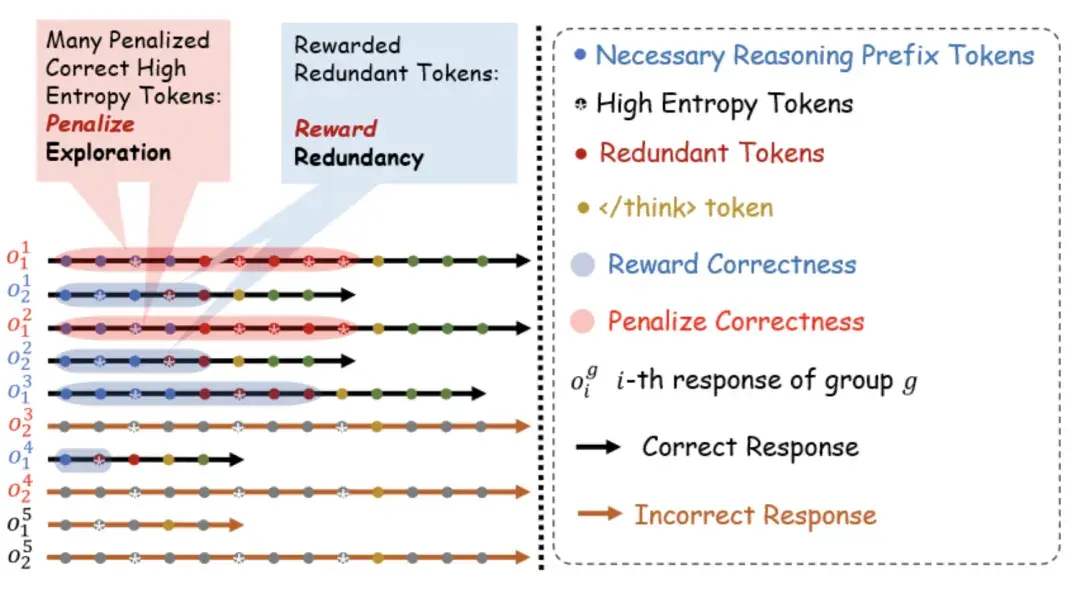
How DECS Fixes Both Bugs at Once?
DECS (which stands for Decoupled Efficiency and Correctness Scheduling) attacks the problem from two directions simultaneously.
Fix #1: Token-Level Reward Decoupling
Instead of punishing the entire answer, DECS teaches the model to recognize which specific tokens matter and which don’t.
The team built a lightweight NRP detector — a small judge model that watches the reasoning process and identifies exactly where the first correct answer appears. Once it finds that point, it draws a line in the sand:
-
Before the line (NRP zone): These tokens are protected. They’re the thinking that led to the answer. No punishment here.
-
After the line (redundant zone): Every single token gets a negative reward. The model learns that continuing past the answer is always wrong.
This is the key insight: Don’t punish thinking. Punish overthinking.
The model can still explore, reconsider, and try different approaches while searching for the answer. But once it finds the answer, it learns to stop immediately. No more “wait, let me check again.” No more “alternatively…” The model gets the freedom to think deeply, but not the freedom to waste time.
Fix #2: Curriculum Batch Scheduling
Even with smart rewards, there’s still a risk. Early in training, the model might confuse “exploration tokens” with “redundant tokens.” A “however” that leads to a better answer might look like waste to the system before the model has fully learned.
DECS solves this with a dynamic training schedule that changes based on how well the model is doing:
-
Early training: When the model still has lots of redundancy, use fewer easy problems in each batch. Easy problems make the model think “short answers work,” which can kill exploration on hard problems.
-
Later training: As the model learns to stop overthinking, gradually add more easy problems back in.
Think of it like teaching a child to ride a bike. You don’t start on a busy street. You start in an empty parking lot, then move to quiet roads, then handle traffic. DECS gives the model a safe space to learn when to stop thinking, before exposing it to the full complexity of real tasks.
The Results: Half the Tokens, Better Answers
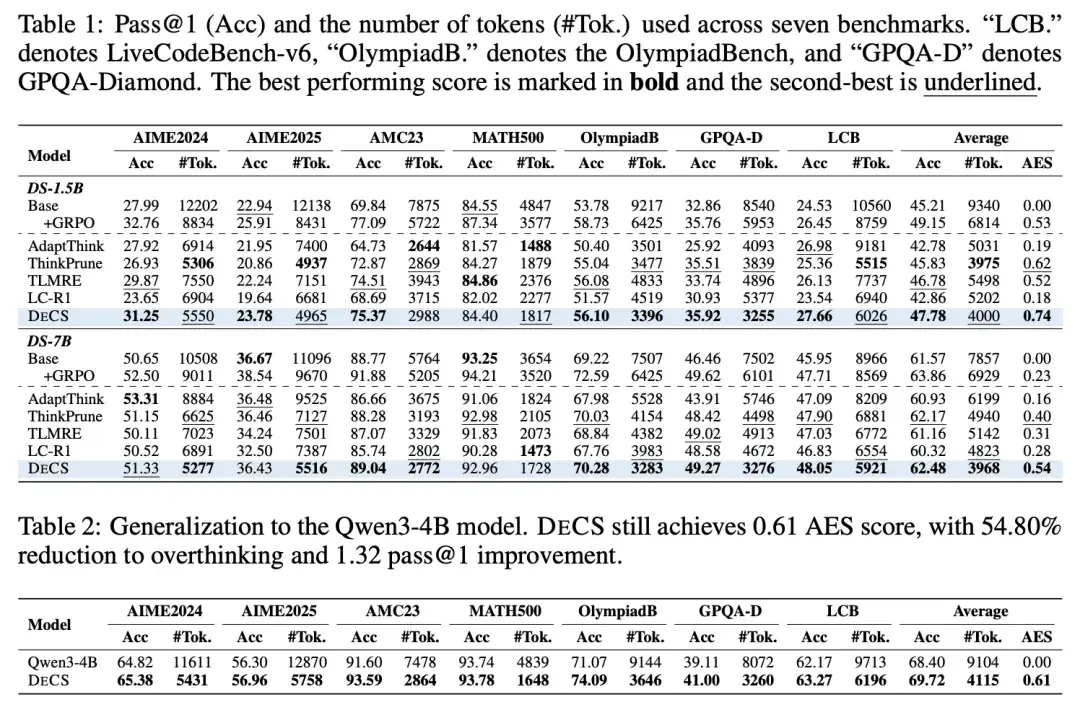
The team tested DECS on three popular AI models: DeepSeek-R1-Distill-1.5B, 7B, and Qwen3-4B. They ran experiments on seven major benchmarks covering math, science, and programming:
-
AIME 2024 & 2025 (math competition problems)
-
MATH500 (standard math benchmark)
-
GPQA-Diamond (graduate-level science questions)
-
LiveCodeBench-v6 (programming challenges)
The Numbers Speak for Themselves
On the 1.5B model:
-
57.17% reduction in average reasoning tokens
-
Pass@1 accuracy improved by 2.48 percentage points
On the 7B model:
-
49.50% reduction in thinking tokens
-
Accuracy improved by 0.8 percentage points
Let that sink in. The model thinks half as much and gets better results. It’s not a trade-off. It’s a genuine improvement on both speed and quality.
Compared to Other Methods
The researchers compared DECS to three leading alternatives: ThinkPrune, TLMRE, and LC-R1. On the combined efficiency-performance score (AES score), DECS won by significant margins — 0.12 and 0.14 points ahead of the best competitors.
The Real Surprise: It Works on Problems It Never Saw
Here’s what makes DECS truly special. The NRP detector was only trained on math problems. But when the researchers tested it on completely different types of tasks, it still worked brilliantly:
-
Science reasoning (GPQA-Diamond): 56.33% token reduction
-
Programming (LiveCodeBench-v6): 33.52% token reduction
This proves that overthinking isn’t a math problem. It’s a universal AI problem. AI models waste tokens the same way across every domain — and DECS fixes the root cause, not just the symptoms.
Why the Ablation Studies Matter?
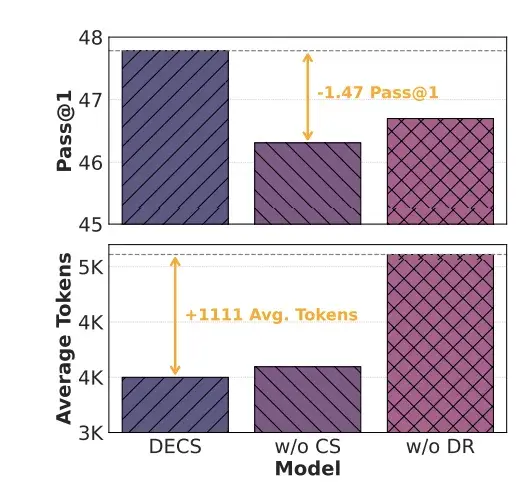
To prove both parts of DECS are necessary, the team ran ablation studies (removing one piece at a time to see what breaks):
Without curriculum scheduling: The model still compressed reasoning, but accuracy dropped significantly. This confirms the researchers’ theory that naive punishment kills exploration. The model learns to be short, but it loses the ability to find hard answers.
Without decoupled rewards: The model kept about 25% of redundant tokens even after training. This proves that sequence-level rewards alone can’t fully eliminate waste. You need to know exactly which tokens to punish.
Only when both pieces work together do you get the full benefit: maximum compression with no accuracy loss.
What This Means for the Future of AI?
DECS isn’t just a clever training trick. It asks a deeper question that the AI industry has mostly ignored: “What isn’t worth thinking about?”
For years, researchers focused on making AI models think more. Bigger models. Longer reasoning chains. More parameters. The assumption was: more thinking = better answers.
DECS proves the opposite. The bottleneck isn’t how much the model can think. It’s how well we teach it when to stop.
For AI Companies:
-
Cut inference costs by 50% without building smaller models
-
Serve more users with the same hardware
-
Reduce energy consumption and environmental impact
-
Speed up responses for real-time applications
For AI Users:
-
Get faster answers from chatbots and assistants
-
Pay less for API calls (most pricing is per-token)
-
Better experience on mobile devices where speed matters
For Researchers:
DECS shows that training objective design matters as much as model architecture. The way you reward a model shapes its behavior more profoundly than its size or data volume. This opens a new research direction: instead of building bigger brains, build better teachers.
Where to Find the Code?
The research team has released DECS as open-source software on GitHub. If you’re running inference for AI models and struggling with costs or latency, this is worth exploring immediately.

-
Project page: https://pixas.github.io/decs-iclr26-site/