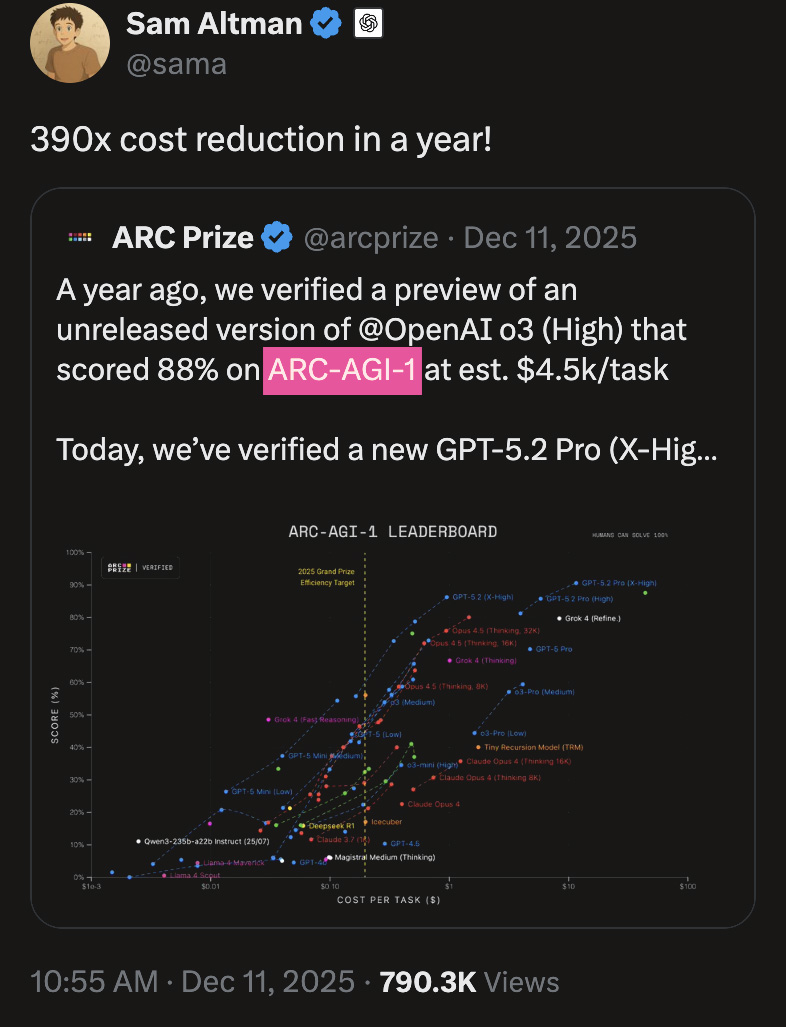
Just moments ago, the world’s hardest AI test turned everything upside down. ARC-AGI-3, the benchmark that top AI models have been struggling to crack, just got shattered by a complete unknown. A tiny company called Symbolica scored a stunning 36.08 percent, crushing every big-name model in the field. Meanwhile, the most powerful AI systems on the planet scored a humiliating 0.2 percent. The entire AI industry is in shock.
This is not just a plot twist. This is an earthquake.
Just hours ago, the ARC-AGI-3 results dropped and the entire AI leaderboard got a brutal shakeup.
The strongest model in the world, Opus 4.6, scored only 0.2 percent. It was a total disaster. But at the same time, a complete unknown came out of nowhere and posted an incredible score.
The entire internet is going crazy. People are calling it the “AGI moment” that everyone has been waiting for. Others say it proves that AGI is not about size. It is about the right approach.
What makes this even more shocking is that just one week ago, ARC-AGI-3 was considered unbeatable.
Then, just moments ago, a company called Symbolica showed up.
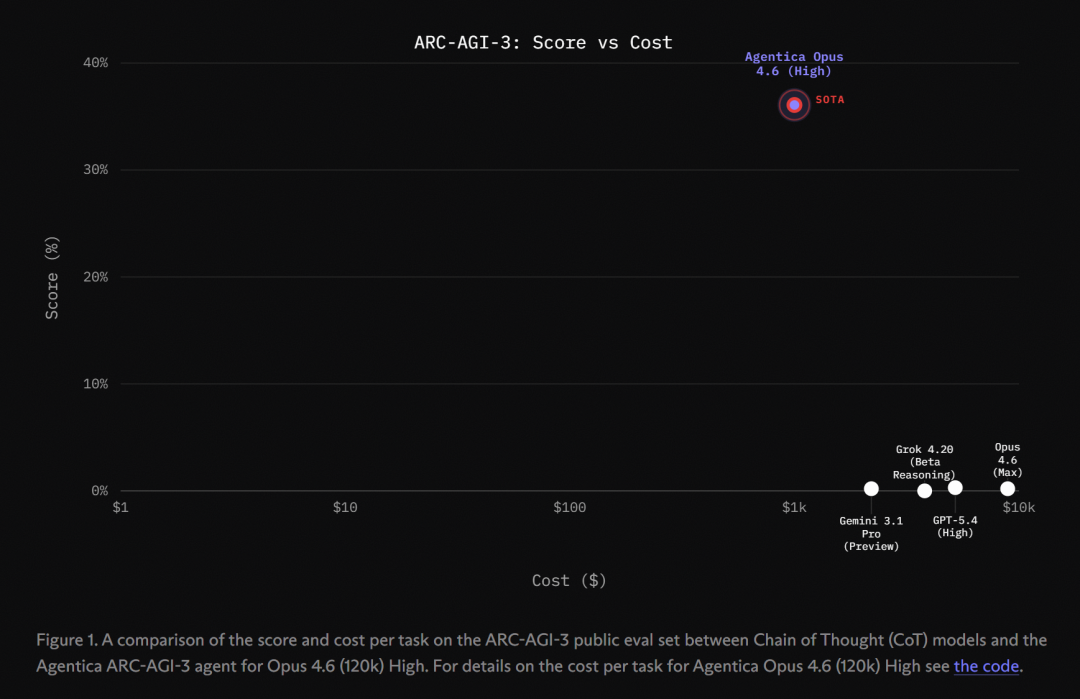
Using a system called Agentica, they scored 36.08 percent on ARC-AGI-3, crushing every CoT model on the planet.


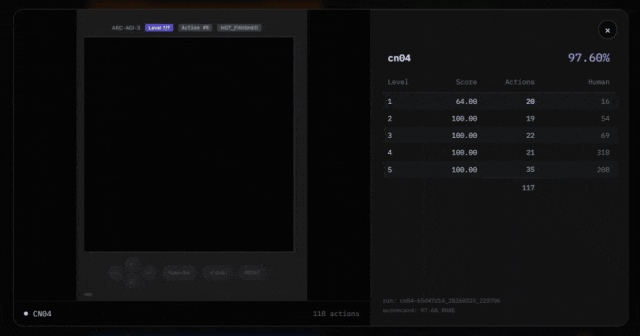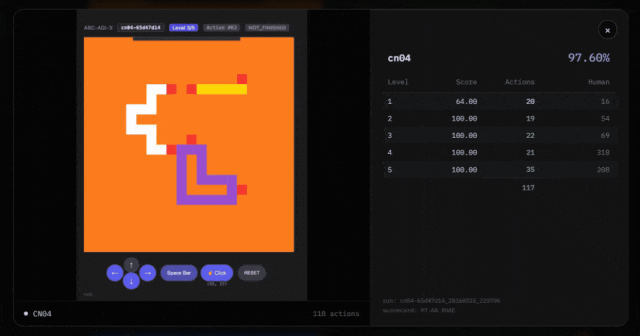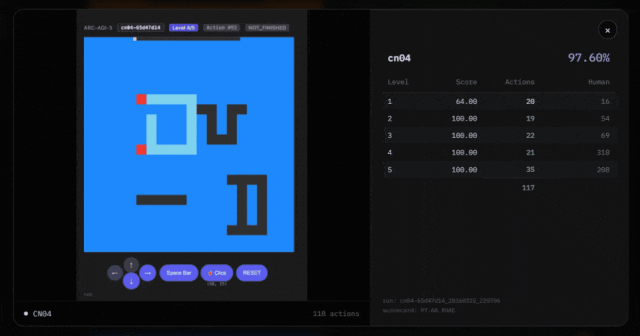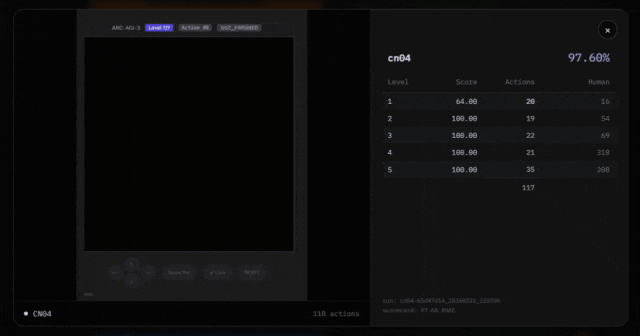
Out of 182 test puzzles, they solved 113. In 25 game categories, they dominated 7 of them.
On the world’s hardest test, this is nothing short of a miracle.
 Symbolica shocks the world with 36 percent
Symbolica shocks the world with 36 percent
Many people thought Opus 4.6 scoring 0.2 percent meant the test was impossible. Now they know better. AGI is not just a marketing game for big companies. The playing field has been leveled by a tiny startup with a better idea.
So how did Symbolica and its Agentica system manage to score a jaw-dropping 36.08 percent on ARC-AGI-3?
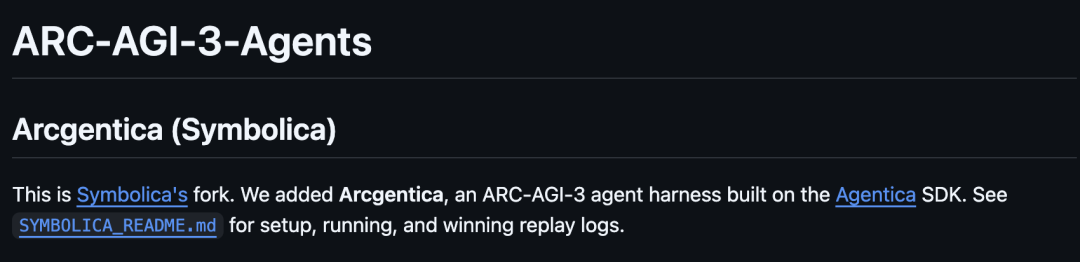
Agentica is Symbolica’s system. Symbolica is a company that builds reasoning systems for ARC-AGI-3.
You need to understand something. ARC-AGI-3 is a completely new test format. The formula is simple: human steps divided by AI steps, squared. Previous models were basically doing brute-force pattern matching. But 36.08 percent means something entirely different. It means real reasoning.

To understand why Symbolica won, you need to understand why Opus 4.6 and GPT-5.4 failed so badly.
ARC-AGI-3 is fundamentally different from previous tests. It is not about pattern matching. It is about reasoning. And reasoning is a game that large language models are terrible at.
When a large language model faces an unknown puzzle, it tries to use its training data. It sees colors, shapes, and positions, and its brain immediately goes to “similar examples” and “water level balance.” Then it gets stuck. It uses CoT, but CoT only works when the pattern is familiar.
But ARC-AGI-3 is designed to break exactly that. It forces AI to think in ways that go beyond memorization. The more the model relies on its training data, the worse it performs.
ARC-AGI-3 is specifically designed to test whether AI can solve problems that are 100 percent unseen. In other words, it tests whether AI can actually think.
But Symbolica’s Agentica system took a completely different path.
Agentica’s core idea is multi-step reasoning with measurable progress. It automatically decomposes problems, generates multiple hypotheses, and then selects the best one.
This means the system can efficiently explore the solution space and find answers that pure memorization could never reach.

Agentica is a new type of safe AI agent system. It can do things that LLMs alone cannot do, such as multi-step reasoning, activity planning, and task execution through an SDK.
Previously, Symbolica had already achieved state-of-the-art results on ARC-AGI-2 using Agentica SDK.

The real secret weapon is the Arcgentica RLM harness
In their GitHub page, in a file called IDEA.md, they describe Agentica’s core weapon for ARC-AGI-3: Agent Harnesses.
GitHub link: https://github.com/symbolica-ai/ARC-AGI-3-Agents
The concept of Agent Harnesses is not new. In fact, it has been mentioned in Anthropic’s official blog and in many industry reports. But Symbolica took it and made it real.
Some people say that if 2025 was the year of AI benchmarks, then 2026 will be the year of agent harnesses.
In the future, every AI model company will need to build harnesses. During testing, each task will be decomposed into smaller subtasks, and each subtask will be handled by a specialized agent.
In this case, Agentica starts with no game knowledge. It has never seen any specific game. But under these conditions, it still solves the test.
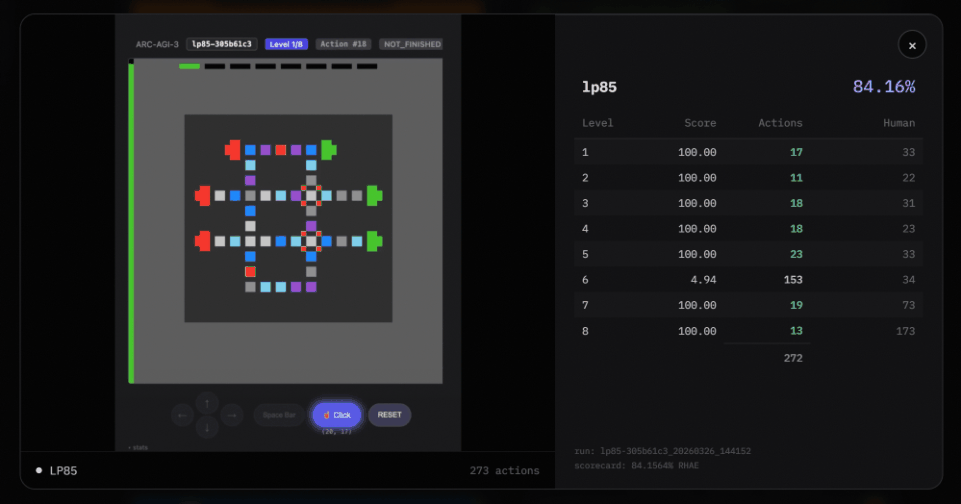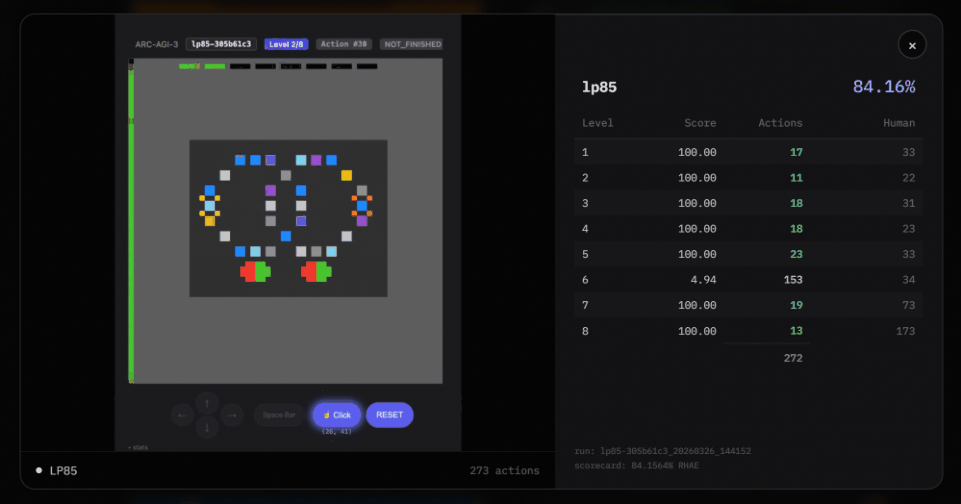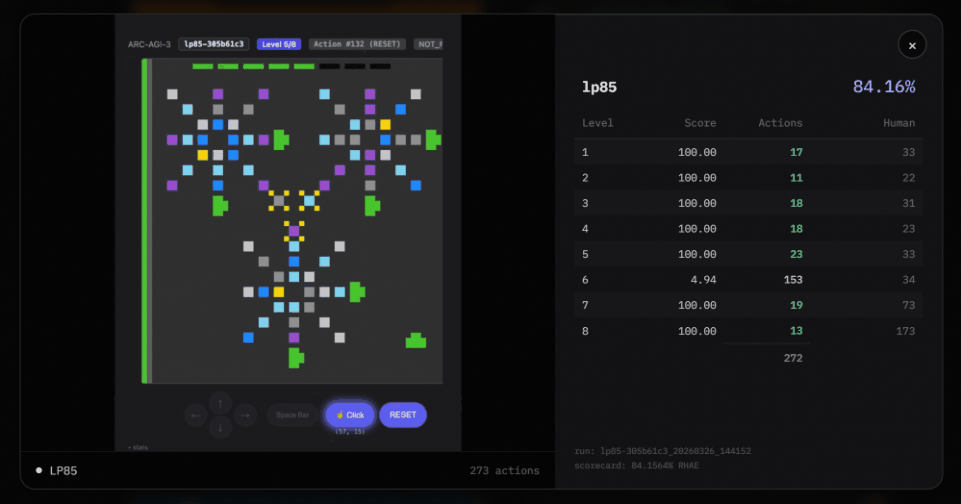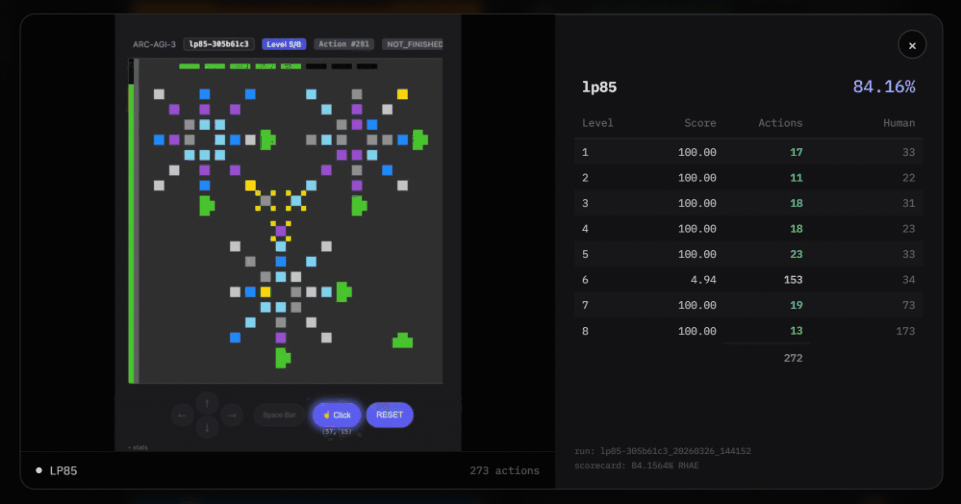
There is a particularly important difference between the Agentica SDK and the Arcgentica RLM system.
First, it is game-agnostic.
ARC-AGI-3 is hard because each game is different. The AI must show that it can generalize. That it has real reasoning ability.
To achieve this, Agentica uses an extreme form of “game-agnostic” design.
It does not know what the colors mean. It does not know what the rules are. It does not know what winning looks like. It only knows that it is playing a game, and it must observe the changes to figure things out.
It starts with a blank slate. Zero knowledge.
Second, it uses a “generalist plus specialist team” model.
The generalist does not directly solve the game. Instead, it decomposes the problem, generates hypotheses, and builds a knowledge base for reasoning.

The specialist team includes explorers, theorists, testers, and solvers.
When a new puzzle arrives, it is immediately decomposed. Each specialist takes a different angle. Some lose their strategic thinking, some generate summaries, some test hypotheses, and some try to reconstruct the original data.
This approach is fundamentally different from the brute-force pattern matching used by models like Opus 4.6. In the same puzzle, Opus 4.6 needs to guess colors, positions, and rules. It lacks the ability to decompose and reason.
That is why it gets stuck. That is why it fails.
During the game, the system maintains a database. It records every action, every confirmed fact, every failed attempt, every winning strategy, and every visual pattern.
Before each new query, it can inherit previous knowledge.
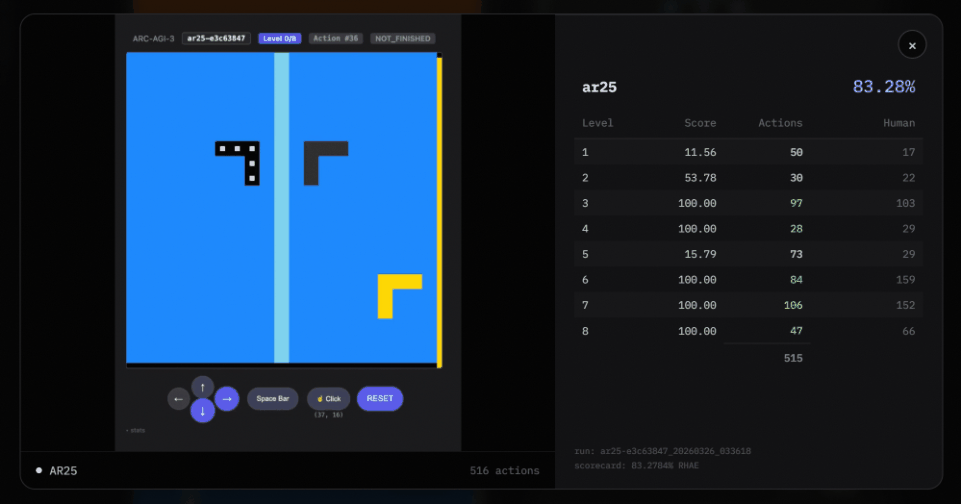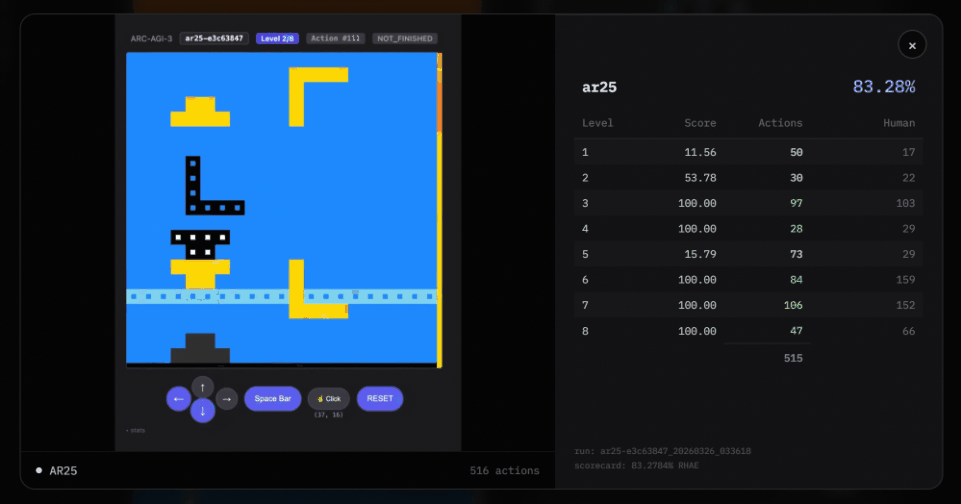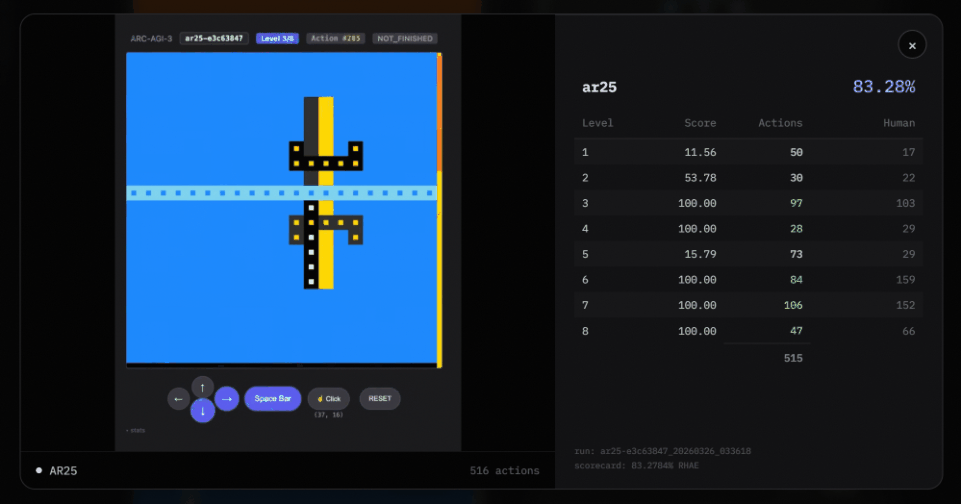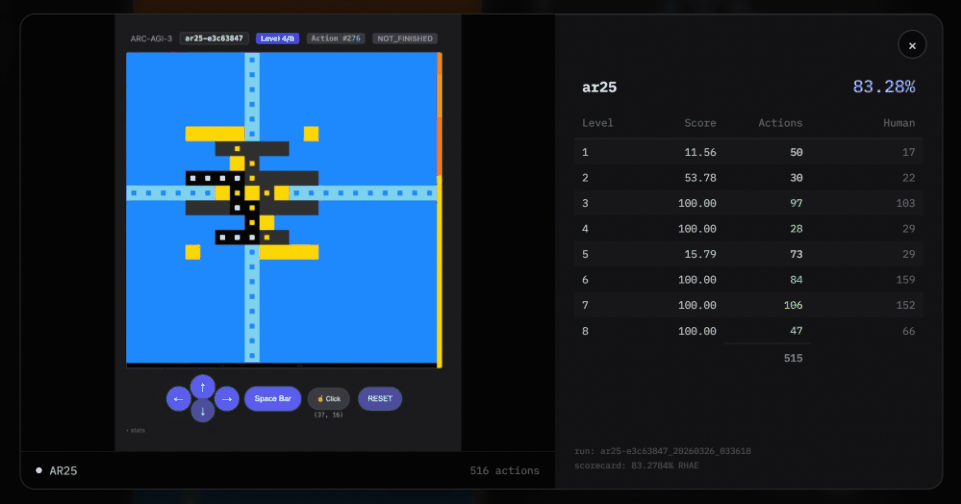
Third, it uses “puzzle transfer learning.”
Puzzle transfer learning means that when one puzzle is solved, the knowledge is directly applied to a new puzzle. But only when the two puzzles share a common pattern.
Agentica uses active prediction. Every token must be grounded in reality.
Each puzzle can be attempted up to 800 times. But the system uses “budget management” to ensure that it does not waste attempts on impossible puzzles.
At the same time, the system makes probabilistic guesses. But these guesses are formal, structured explorations.
Moreover, the system needs to use multiple tools. It needs to balance authority between different agents.
You need to know that the official positioning of ARC-AGI-3 requires strong reasoning, exploration, planning, judgment, memory, goal extraction, and tool use.
Agentica’s architecture is specifically designed for these “hardcore” abilities.
Exploration: The system uses explorers to actively predict and execute. They use partial observations to extract patterns and generate hypotheses.
Planning and rule inference: The system uses theorists to build rule sets. They use submit_action to test rule frequencies and build dynamic rule sets.
Memory: A memories database records every puzzle in a structured way. Each puzzle gets its own branch. The system uses “repeated learning” to reduce token costs.
Goal extraction: The levels_completed metric tracks progress. The orchestrator uses this data to optimize the exploration loop.
Of course, this is just the basic structure of ARC-AGI-3. In practice, authority overlap, efficiency balance, and cost control are extremely complex. The system needs to handle “information overload,” “tool selection,” and “reality alignment.” In fact, the entire test is not about transferring to a single authority puzzle.

Is the 36.08 percent score real?
Of course, a 36 percent score is controversial. Before ARC Prize officially verified it, Symbolica’s “self-reported” score naturally attracted skepticism.
Symbolica also admitted that this score has not yet received official verification from ARC-AGI-3.

There is a very important note here: “unverified competition score.”
Symbolica’s current score is based on a self-built environment that replicates the official test process. It needs further verification.
Moreover, there are some suspicious details in the score breakdown.
For example, Symbolica claims to have obtained high scores through the ARC-AGI-3 API. In the cn04 game, they passed 6 puzzles. But the number of puzzles obtained through the API may not match the actual game.
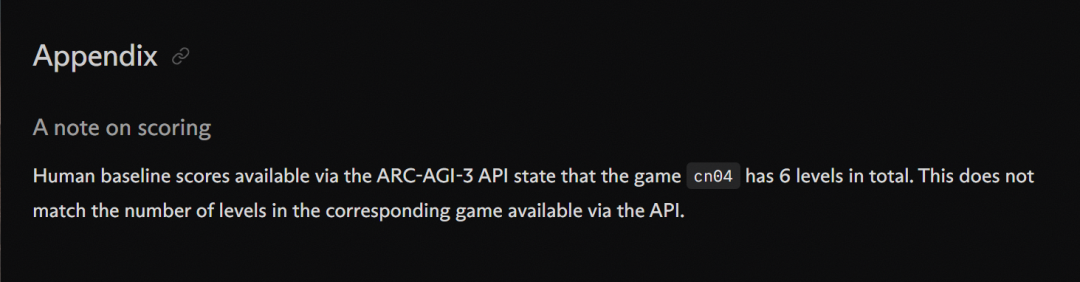
There may also be version differences in the official data, which could affect the results.
Moreover, in the score breakdown chart, you can see that some single games scored extremely high, between 80 and 97 percent, while others scored extremely low, between 0.2 and 0.7 percent.
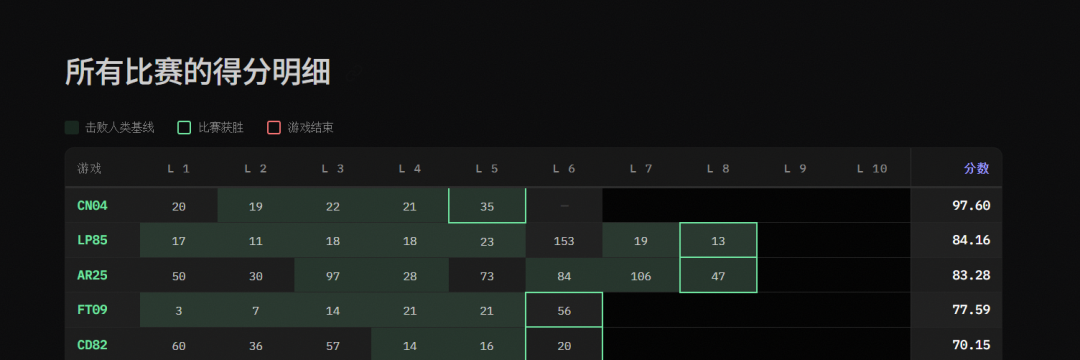

This extreme polarization raises the question: Is this a real general ability, or is it just overfitting to specific game types?
Objectively speaking, if the system can indeed generalize, it should show relatively consistent performance across different games.
 The real meaning of ARC-AGI-3
The real meaning of ARC-AGI-3
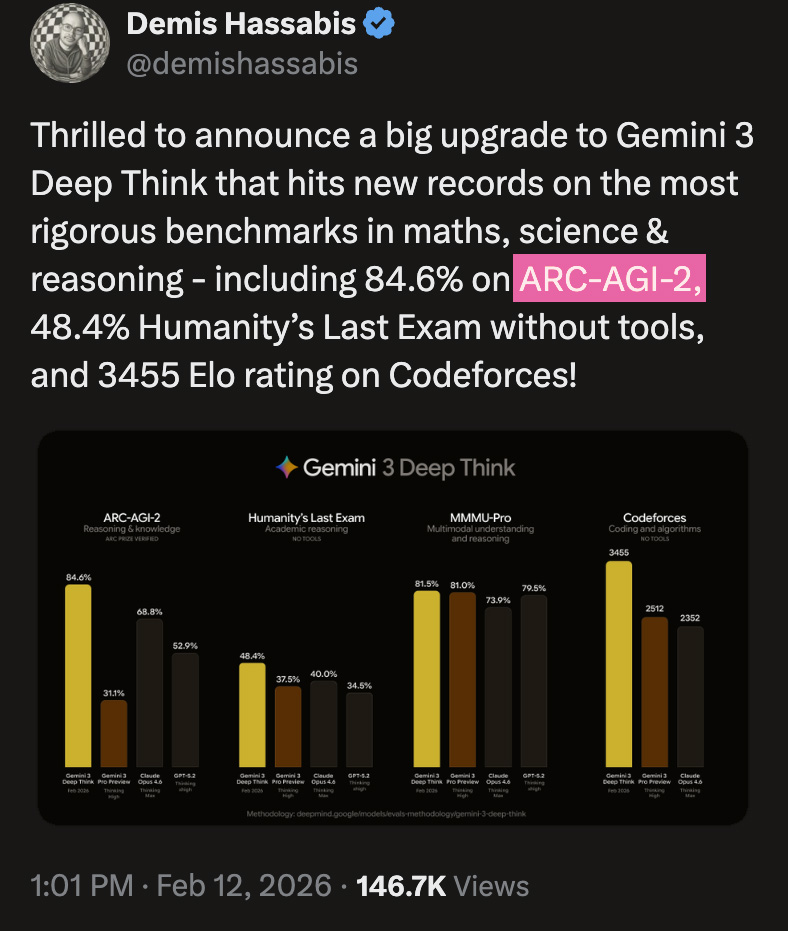
Today, ARC-AGI-3 has suddenly become the new standard for testing AGI. OpenAI, xAI, and other top AI companies are all paying close attention.
 ai nudifier
ai nudifier
Click below to see more
When ARC-AGI-3 was officially released, many people were stunned by its difficulty.
 cuckold chat
cuckold chat
Some people think this new benchmark is the real starting point for AGI. Others believe that the AI reasoning problem has been completely exposed by this static benchmark. However, the OpenClaw team, which calls itself “the dark horse,” has already thrown a formal challenge to the industry. They say that the real test is not about who can explore deeper, but about who can plan better and execute more directly.
ai porn gen
Competition link: https://www.kaggle.com/competitions/arc-prize-2026-arc-agi-3/data
The core challenge of ARC-AGI-3 is to test whether AI can completely solve problems in an unfamiliar environment. In other words, can it show true generalization ability?

ARC AGI 3 technical report link:
https://arcprize.org/media/ARC_AGI_3_Technical_Report.pdf
In short, each game requires the AI to explore, understand, and solve from scratch. 100 percent means the AI can completely solve an unfamiliar game in one try.
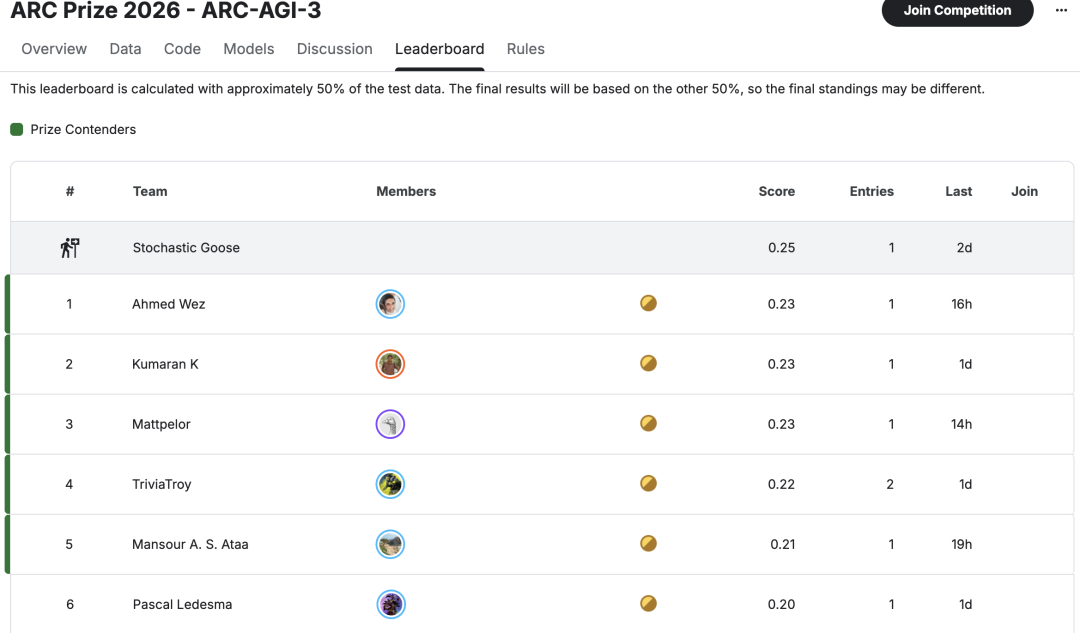
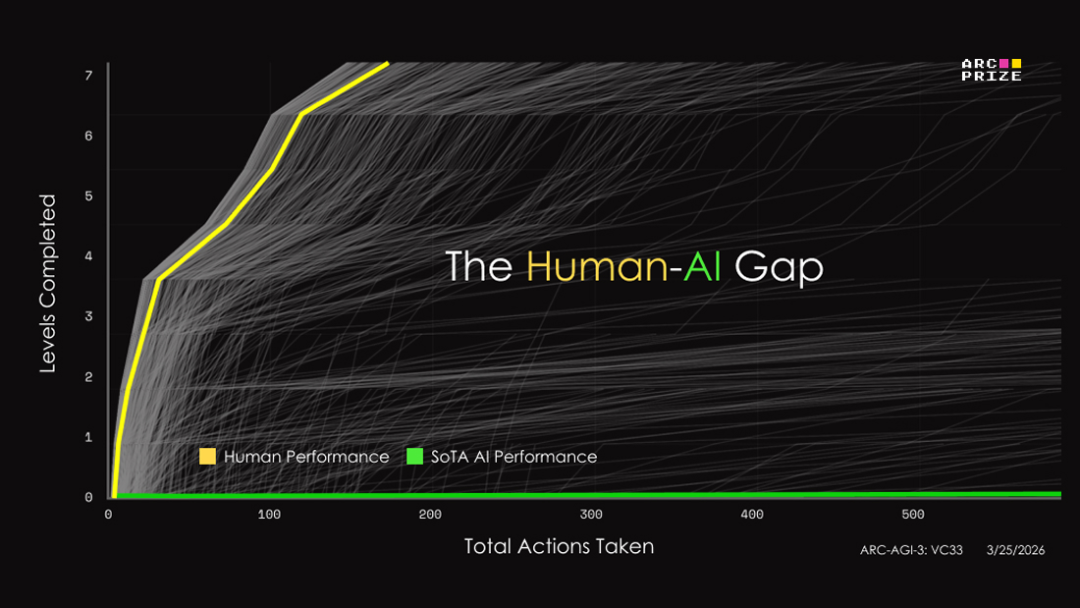
The current human score is 0.25, which means humans can only solve 25 percent of the puzzles.

What ARC-AGI-3 really tests is not whether AI is smart. It is whether AI can think in a completely new way. It is not about memorizing patterns. It is about real reasoning.
The key point is that ARC-AGI-3 also released the K-level, which is a summary of past human experiences. It points to different types of reasoning:
First, agentic thinking. This is a new way of thinking.
It means using your own experience to learn. Just like a human child learns by playing, an AI system should also have the authority to simulate, execute, observe, verify, and learn.

In this process, the model uses active thinking. It generates multiple hypotheses, focuses attention, enters loops, and makes progress through continuous feedback.
It means that when AI faces an unknown puzzle, it must have enough time to transform from “model memorization” to “model reasoning.”
The core purpose of ARC-AGI-3 is to force AI to think in this way. And Symbolica just proved that it is possible.
After this, the entire AI industry faces a huge question.