NVIDIA just entered the AI agent wars. Their new open-source model, Nemotron 3 Super, is built specifically for agents. It has 120 billion parameters. It processes 100,000 tokens at once. And it is already beating Claude Opus 4.6 on key benchmarks.
This is not just another model release. This is NVIDIA declaring that the future of AI belongs to open-source agents. And they are putting serious money behind that bet.

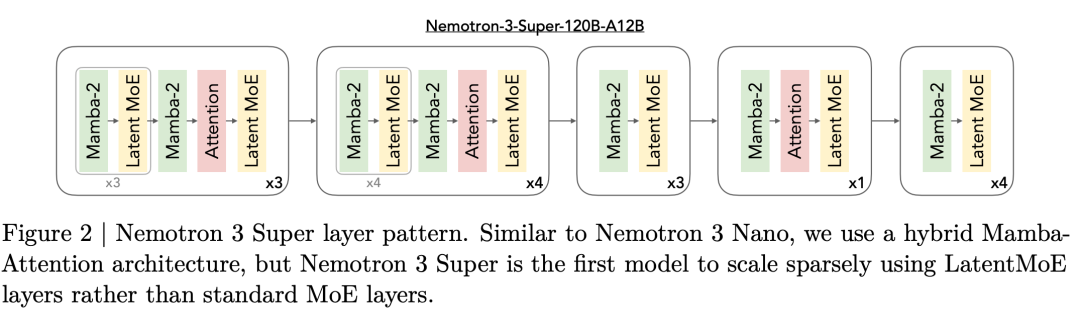
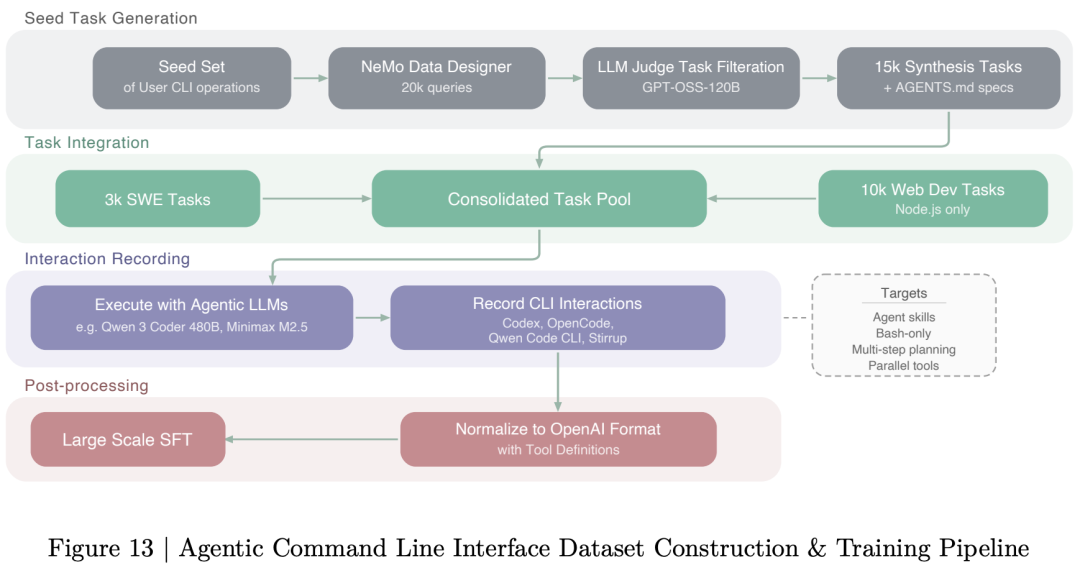
Here is what makes this release special. Nemotron 3 Super introduces a brand new Mamba-MoE hybrid architecture. It is the first model to solve two major problems that have been slowing down AI agents. The token bottleneck and the thinking tax.
Let us break down what that means and why it matters for every developer building with AI in 2026.
The Benchmarks That Turned Heads
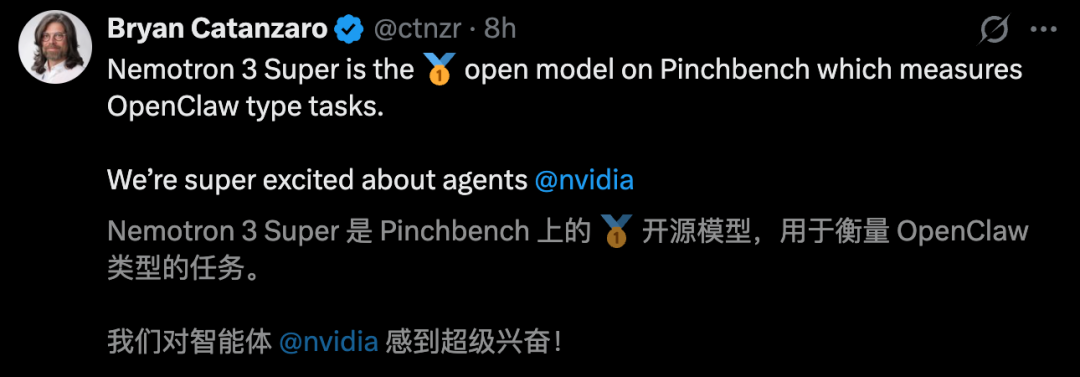
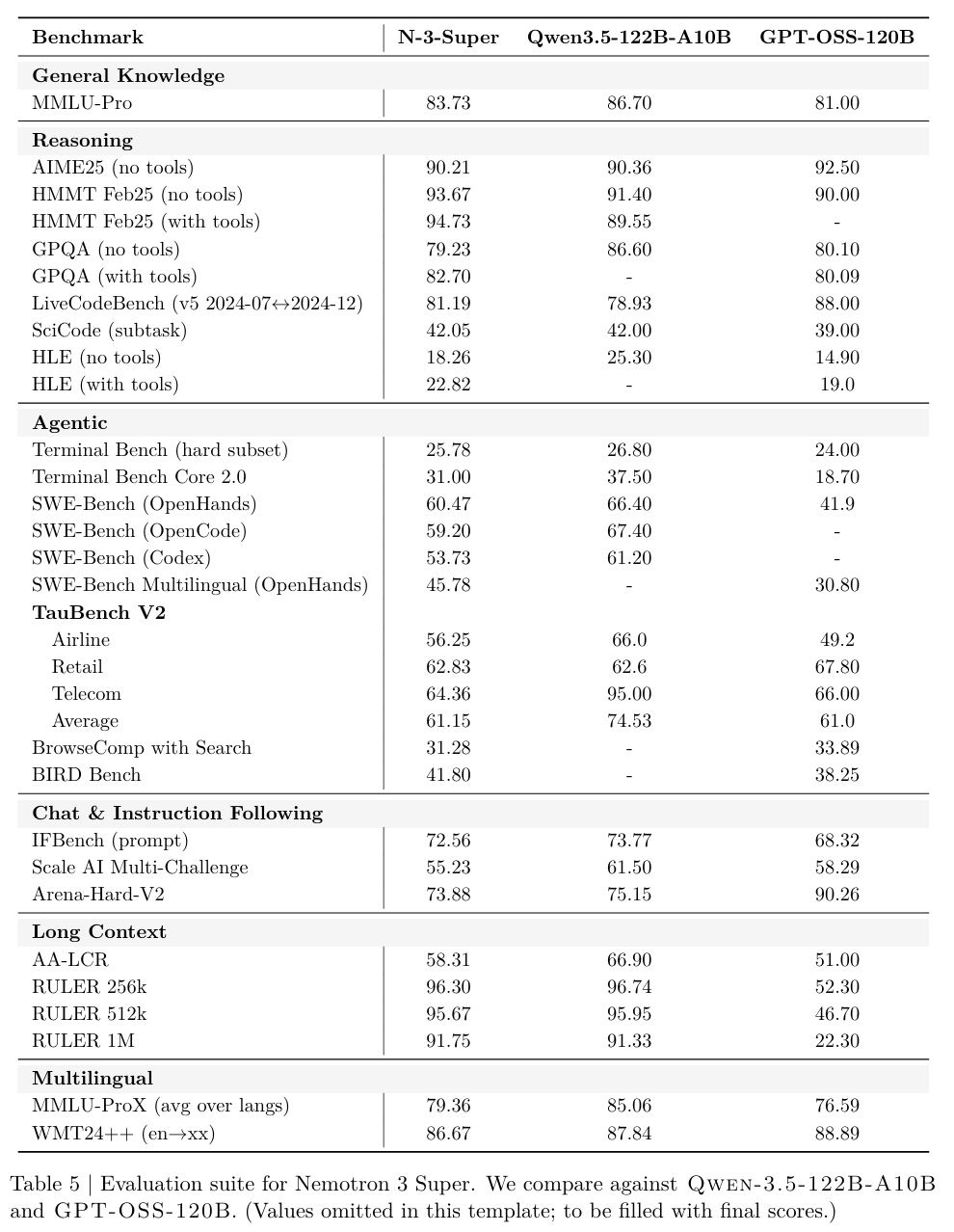
On Pinchbench, which measures real-world agent performance, Nemotron 3 Super scored 85.6%. That puts it right next to Claude Opus 4.6 and GPT-5.4. For an open-source model, this is unheard of.
On Artificial Analysis, which tracks both performance and efficiency, Nemotron 3 Super set a new state-of-the-art record. Among models of similar size, its accuracy is far ahead of the competition.
NVIDIA also tested the model on their own AI-Q research benchmarks, DeepResearch Bench and DeepResearch Bench II. Nemotron 3 Super ranked first on both.
The model is fully open-source. You can download it today from Hugging Face. The weights are free. The training data is documented. And NVIDIA has pledged $26 billion over the next five years to build the world’s best open-source AI models.
Solving the Two Biggest Agent Problems
AI agents have a dirty secret. They waste tokens. Lots of them.
Every time an agent takes an action, it needs to resend its entire conversation history, its memory, its tool definitions, and its current goal. For long-running tasks, this creates a massive token drain. Costs explode. Latency spikes. And worst of all, the agent can lose track of its original mission. This is called goal drift.
The second problem is the thinking tax. Complex agents often need to reason through multiple steps before taking action. Each reasoning step calls the language model again. This makes agent applications expensive and slow. In many real-world scenarios, the cost becomes prohibitive.
NVIDIA built Nemotron 3 Super specifically to attack both problems.

cumshot generator
The Architecture: Mamba Meets Mixture of Experts
Nemotron 3 Super uses a hybrid architecture that combines three breakthrough technologies.
First, Mamba-2 layers. Unlike traditional Transformer attention, which gets slower as sequences get longer, Mamba-2 maintains near-constant speed. It uses structured state space models to track long-range dependencies without the quadratic cost of attention. For agents that need to remember conversations from thousands of tokens ago, this is a game changer.
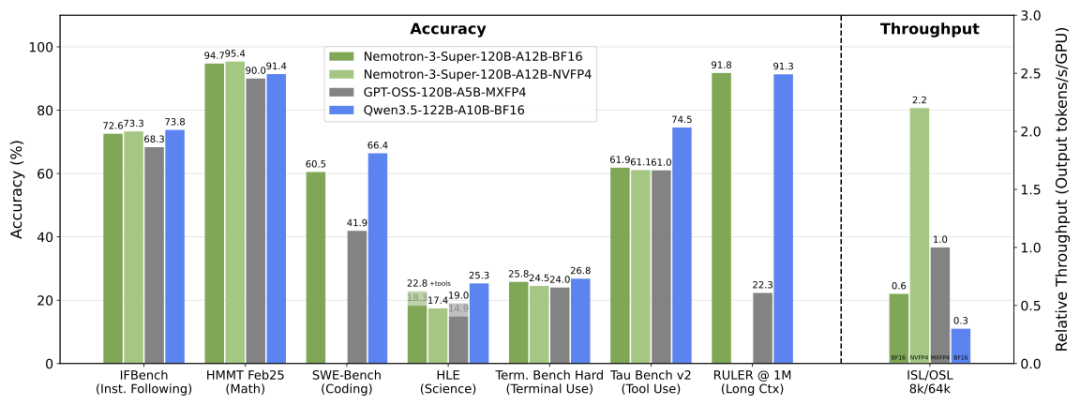
Compared to other open models like GPT-OSS-120B and Qwen3.5-122B, Nemotron 3 Super is dramatically faster at long contexts. At 8,000 tokens, it is competitive. At 64,000 tokens, it outperforms GPT-OSS-120B by 2.2 times and Qwen3.5-122B by 7.5 times. This is not a small improvement. It is an order-of-magnitude leap.
Second, LatentMoE. This is NVIDIA’s new Mixture of Experts design. Traditional MoE models route tokens to experts based on surface-level patterns. LatentMoE compresses tokens into a smaller latent space before routing. Both the router and the experts operate on this compressed representation.
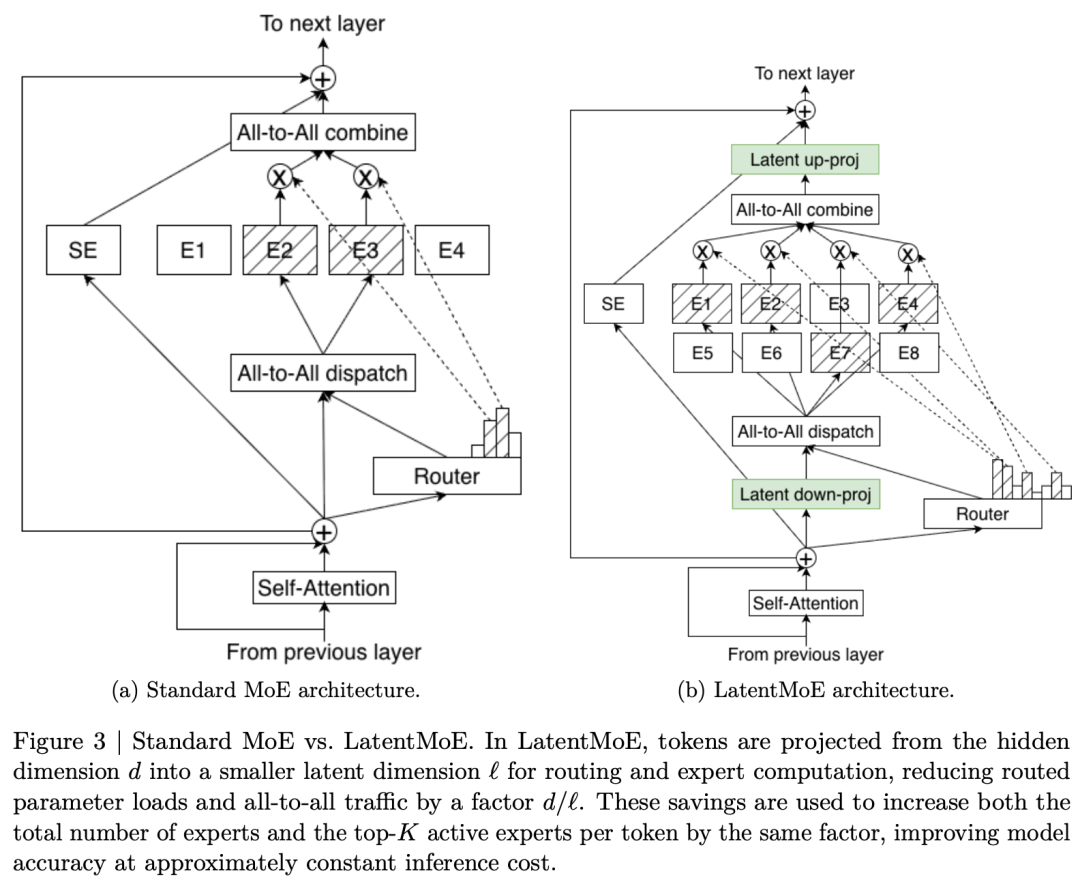
What does this mean in practice? Important tokens get more expert attention. Common tokens get shared efficiently. Each expert sees richer, more diverse text. And the whole system uses less memory.
NVIDIA’s own numbers show that one expert in LatentMoE matches the capacity of four experts in traditional MoE. On both training efficiency and inference speed, LatentMoE wins decisively.
Third, Multi-Token Prediction. Instead of predicting one token at a time, Nemotron 3 Super predicts multiple future tokens at each position. During training, this forces the model to learn deeper structural patterns. During inference, it enables speculative decoding.
Here is how speculative decoding works. A small draft model quickly generates candidate tokens. The main model then verifies them in parallel. Correct tokens are accepted. Wrong tokens are corrected. The result is faster generation with almost no extra compute cost.
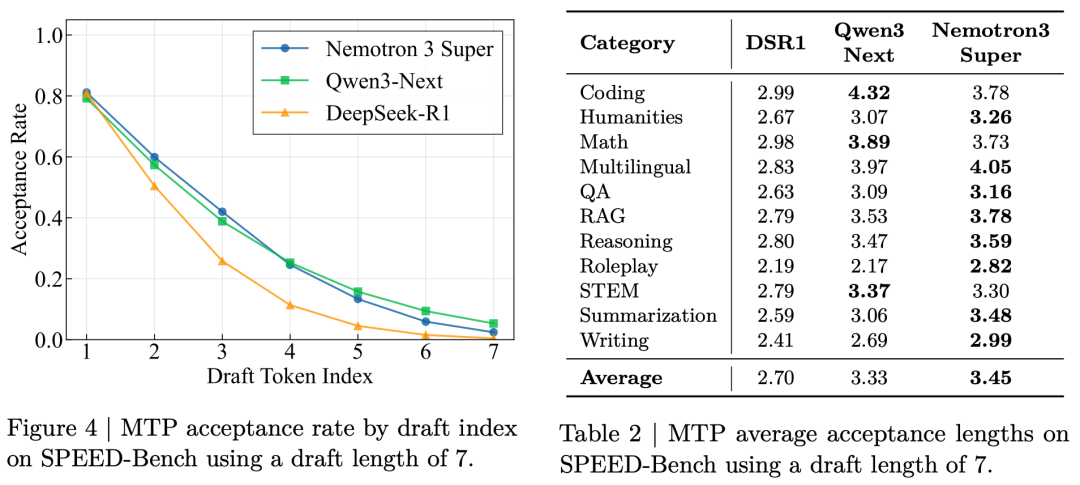
Training on 25 Trillion Tokens
Nemotron 3 Super was trained on 25 trillion tokens. The process had two stages.
The first stage used 80% of the data, about 20 trillion tokens. This was general pre-training across 16 trillion web pages, books, code, and math. The goal was broad knowledge.
The second stage used the remaining 20%, about 5 trillion tokens. This was high-quality curated data from academic papers, PDFs, STEM materials, and authoritative sources. The goal was depth and accuracy.
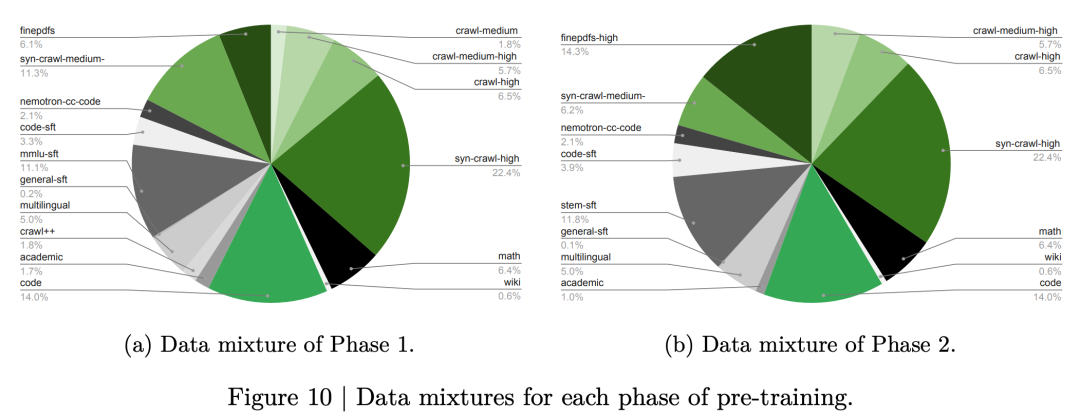
The results speak for themselves. On MMLU, the model scores 86.01. On MMLU-Pro, 75.65. On MATH, 84.84. These numbers crush most open-source competitors.
After pre-training, NVIDIA went heavy on agent-specific training. The supervised fine-tuning stage used over 700,000 conversations totaling 800 billion tokens. Agent tasks made up 36% of this data. Multi-turn dialogue was 23%. Reasoning tasks were 31%.
The reinforcement learning stage was even more aggressive. They used 21 rounds of RLVR across 37 datasets covering math, STEM, coding, dialogue, and agent loops. Each round used 256 prompts with 16 responses per prompt. Then came SWE-RL, specialized training for software engineering with 20 billion tokens. Finally, RLHF with 18 billion tokens using a Qwen3-235B reward model for safety and helpfulness.
What This Means for OpenClaw Users
Nemotron 3 Super is not just a research paper. It is a production-ready tool. And it is already being integrated into agent platforms.
Perplexity has added Nemotron 3 Super as one of the top 20 models in their Computer feature. Companies like CodeRabbit, Factory, and Greptile are using it to power their AI code review agents. Scientific startups like Edison Scientific and Lila Sciences are using it for drug discovery and protein structure analysis.
But the biggest news is NVIDIA’s plan to enter the OpenClaw ecosystem directly.
According to WIRED, NVIDIA is building an open-source AI agent platform called NemoClaw. The name says it all. Nemo comes from Nemotron. Claw comes from OpenClaw. This is not a subtle move. NVIDIA wants to own both the model layer and the platform layer.
NemoClaw is reportedly starting as a fully private enterprise tool for automated coding. But the long-term vision is clear. NVIDIA wants to sell chips. The more AI agents people run, the more GPUs they need. By open-sourcing the software stack, NVIDIA makes it easier for companies to deploy agents at scale. And every deployment means more GPU sales.
This is a brilliant strategy. OpenClaw proved that developers want open, model-agnostic agent platforms. NVIDIA is now saying, we will give you the best open-source model, the best open-source platform, and the best hardware to run it on. The full stack.
For OpenClaw, this is both a threat and an opportunity. Competition will force faster innovation. But NVIDIA’s entry also validates the entire open-source agent market. When a $3 trillion company bets on your category, you know you are onto something big.
Why This Matters for the Future of AI
The AI industry is splitting into two camps. Closed ecosystems and open ecosystems.
Closed ecosystems like OpenAI and Anthropic offer powerful models but lock you into their platforms. Open ecosystems like OpenClaw, Nemotron, and the broader open-source community give you freedom but require more setup.
NVIDIA is betting that open will win. And they are putting $26 billion behind that bet.
Nemotron 3 Super is the first shot in that war. It proves that open-source models can match closed-source flagships on real tasks. It introduces new architectures that solve real problems. And it comes from a company that controls the hardware layer.
For developers, the message is clear. You no longer need to choose between performance and freedom. You can have both. You can build agents on open-source models that rival Claude and GPT. You can customize them. You can host them on your own infrastructure. And you can switch between models as the market evolves.
The age of the AI agent is here. And thanks to NVIDIA, the best tools to build them are now open-source.
Are you planning to try Nemotron 3 Super? Let us know in the comments. And subscribe for weekly updates on open-source AI models and agent platforms.