
One paper from Google just crashed the memory chip market. The new TurboQuant algorithm compresses AI model memory to 3-bit precision. Memory usage drops to one sixth of current levels. Inference speed jumps by eight times. Wall Street did not see this coming.
Chip stocks are bleeding. Micron fell 4 percent. Samsung dropped 4.4 percent. SK Hynix lost 5.6 percent. Even Nvidia, the AI darling, sank 6.5 percent. Investors suddenly realized that the memory boom might be built on sand.
The panic started when Google published TurboQuant. This algorithm attacks the biggest hidden cost in AI inference. It is called the KV cache, and it undress ai promo codeis eating memory alive.

Here is why this matters. When large language models generate text, they must remember every previous word. This memory is stored as key-value pairs, called the KV cache. As conversations get longer, this cache grows like a snowball rolling downhill. For long contexts, it becomes the memory bottleneck that stops models from running on normal hardware.
Google’s TurboQuant solves this with a two-stage compression system. First, it rotates the data using a mathematical transform. Then it compresses each value to just 1 bit. The result is a 6 times reduction in memory usage with almost zero loss in quality.

The paper was accepted at ICLR 2026, one of the top AI conferences. The results are shocking. Without any retraining, TurboQuant compresses KV cache memory down to 3-bit precision. On an H100 GPU, compared to 32-bit baseline, 4-bit TurboQuant runs 8 times faster while saving massive memory space. Performance actually improves.

For memory chip makers, this is an earthquake. The entire AI hardware stack rests on the assumption that models need massive memory. Nvidia’s expensive H100 chips, the high-bandwidth memory from Samsung and SK Hynix, the data center buildouts worth billions. All of it depends on memory hunger.

TurboQuant directly challenges that assumption. If KV cache drops by 6 times and speed rises by 8 times, every AI server needs fewer high-end memory chips. The demand curve that chip makers have been counting on suddenly looks wrong.
Cloudflare CEO Matthew Prince compared the moment to when DeepSeek shocked the industry. Another paradigm shift. Another reason to question whether hardware investments will pay off.

To understand why TurboQuant works so well, we need to look at the KV cache problem. When a language model processes each word, it must look back at all previous words. To avoid recalculating everything, the model stores key and value vectors for every attention head. This creates a growing memory table.
As context length expands from 4K to 128K tokens, the KV cache grows exponentially. For large models, it becomes the primary memory bottleneck. Traditional solutions compress from 16-bit to 4-bit, but this creates quality loss.

TurboQuant takes a completely different approach. It uses a two-stage pipeline that sounds like magic but is grounded in solid math.
Stage one is called PolarQuant. Instead of storing values in the standard X, Y, Z coordinate system, PolarQuant rotates the data into a polar coordinate system. In this new system, each value is described by a radius and an angle.
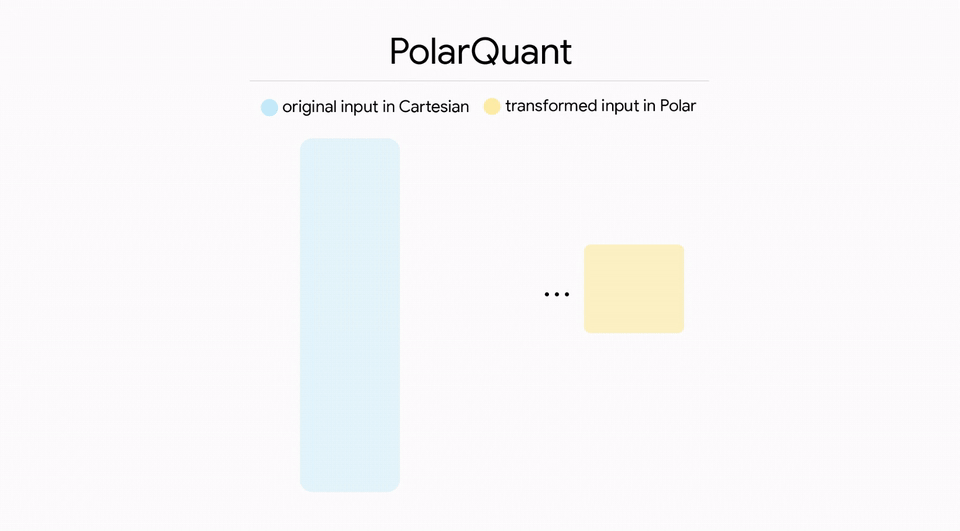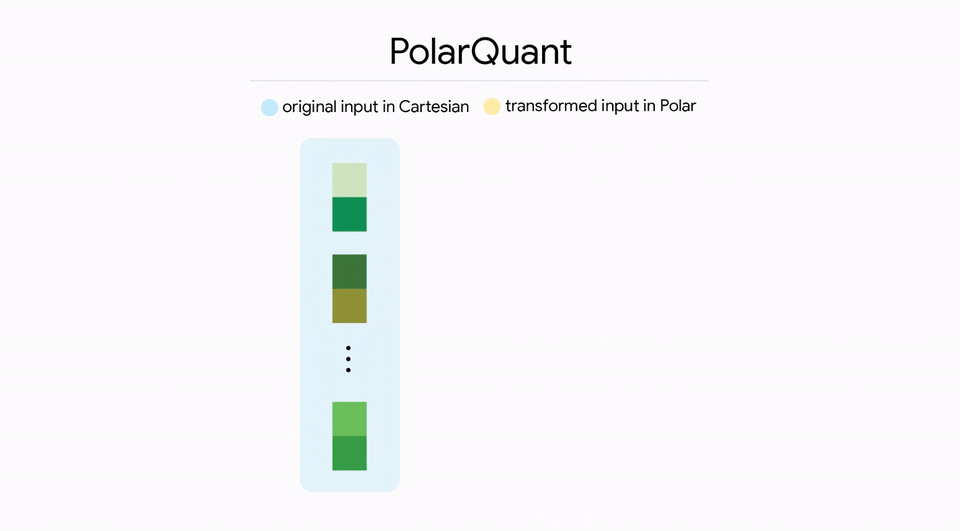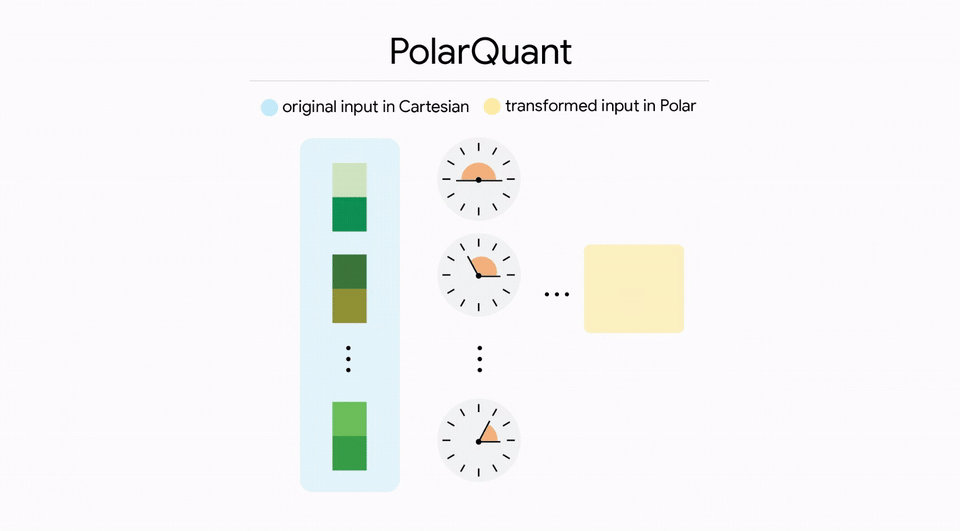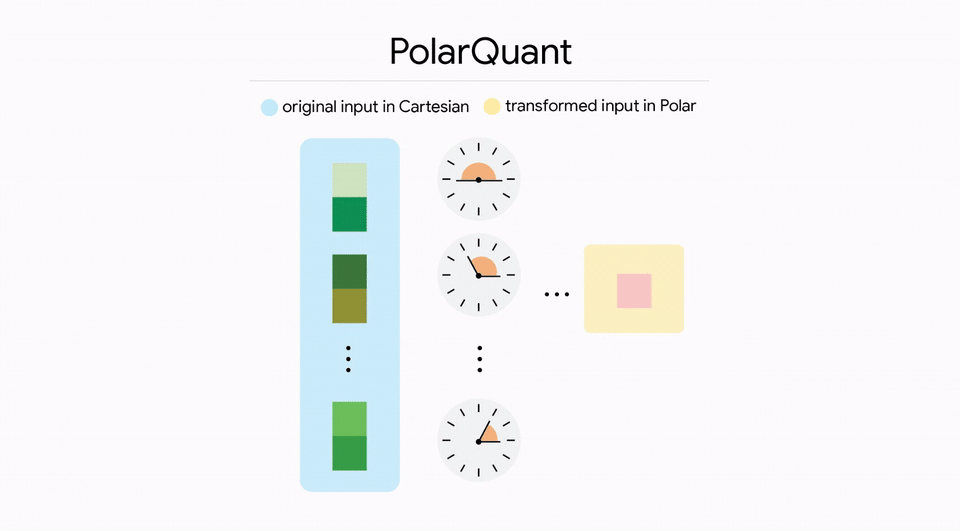
The genius insight is that in high-dimensional spaces, data points tend to cluster in specific directions. By rotating to align with these clusters, PolarQuant can describe most values with just a radius and a small angle deviation. The original data distribution becomes a simple pattern.
Stage two is called QJL, which applies 1-bit calibration. This is where the real compression happens. Using a mathematical technique called the Johnson-Lindenstrauss transform, TurboQuant compresses each value to just 1 bit plus a sign. The trick is using high-precision query vectors with low-precision compressed key vectors during attention calculation.
The math guarantees that the systematic bias from stage one is completely canceled out. With just 1 bit, the error from the first stage is smoothed away. The result is near-lossless compression at an unbelievable ratio.
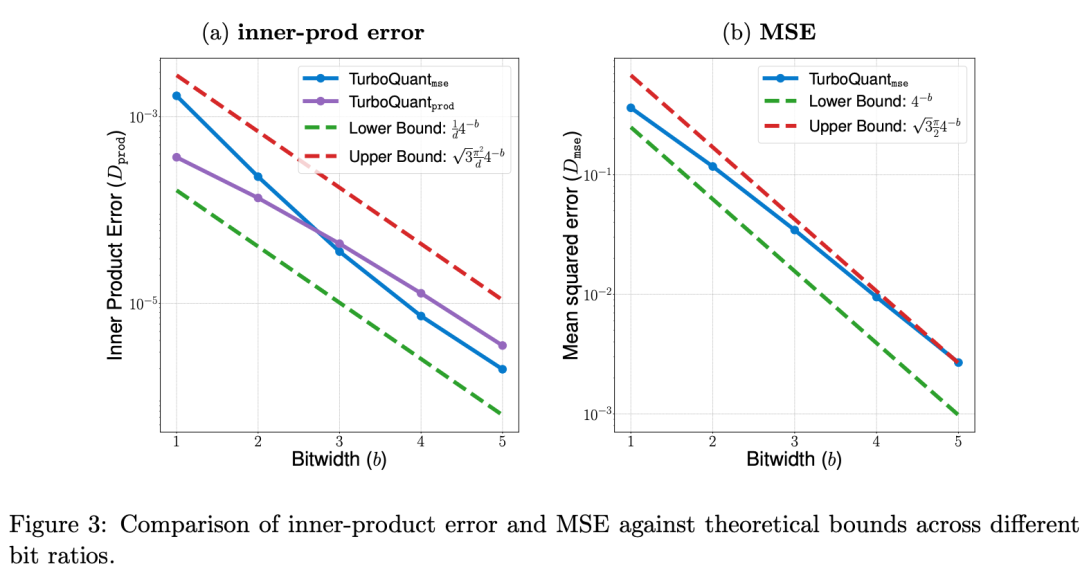
The algorithm is data-oblivious. It needs no calibration data, no pre-training, and no dataset tuning. At the same time, it avoids traditional quantization problems like lookup tables and distribution assumptions. It runs efficiently on GPUs.
The results speak for themselves. On the LongBench benchmark covering question answering, summarization, and coding tasks, 3-bit TurboQuant matches or beats current state-of-the-art methods across all models. On the needle-in-a-haystack test, where a specific piece of information is hidden in a long text, TurboQuant at 4-bit compression locates the needle at 10.4 thousand tokens. At 6-bit compression, the model catches every needle without missing a single one.
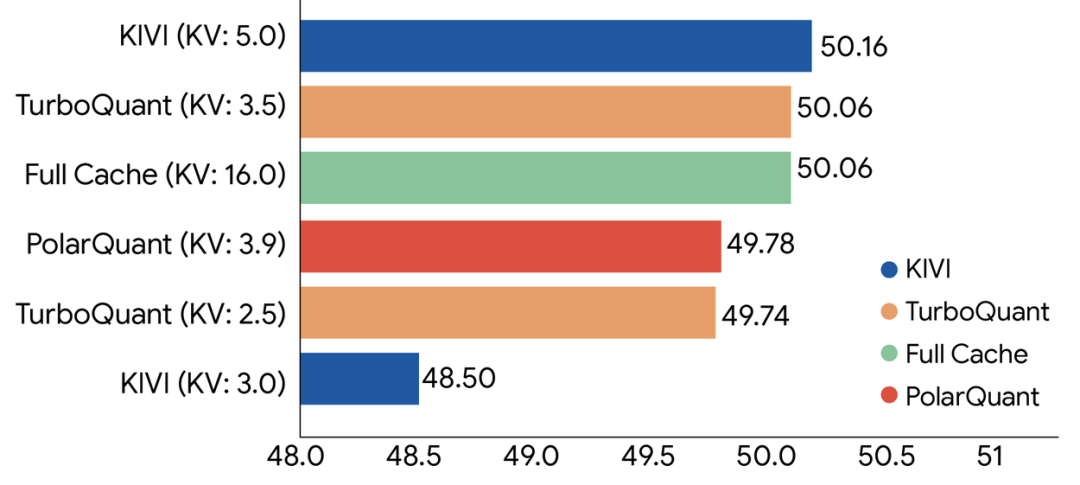
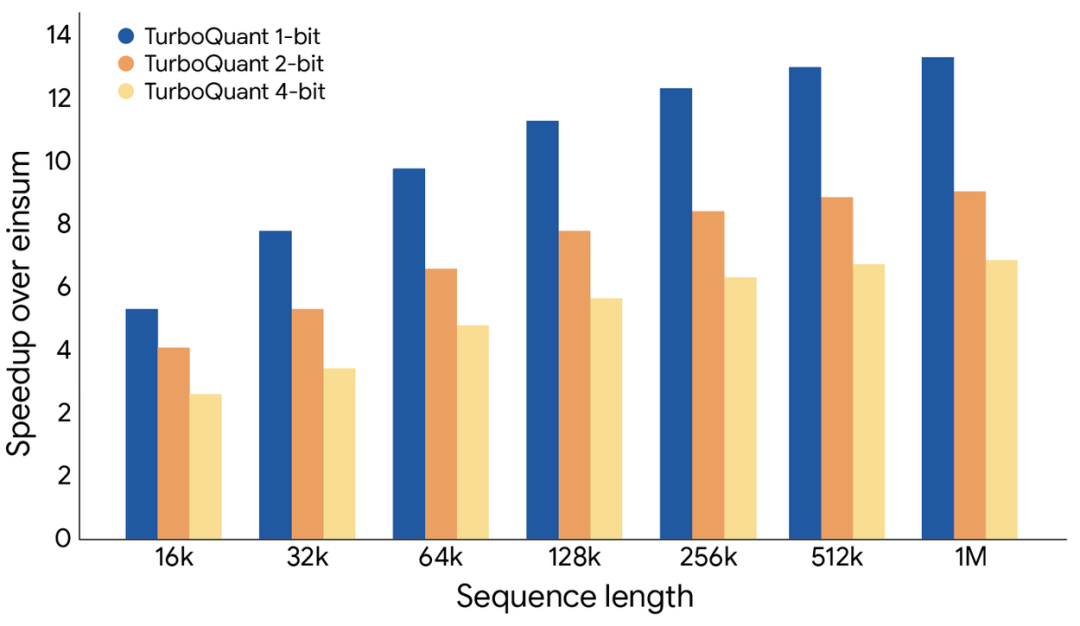
On H100 GPUs, 4-bit TurboQuant achieves 8 times speedup in attention logits calculation compared to 32-bit baseline. The key point is that this 8 times speedup applies to the attention loop, which is the shallow part of the network where most compute resources are consumed.
Google emphasizes that TurboQuant maintains high accuracy during inference and is easy to deploy. The algorithm involves no dataset-specific parameters. Everything is deterministic, making it naturally suitable for GPU kernels.
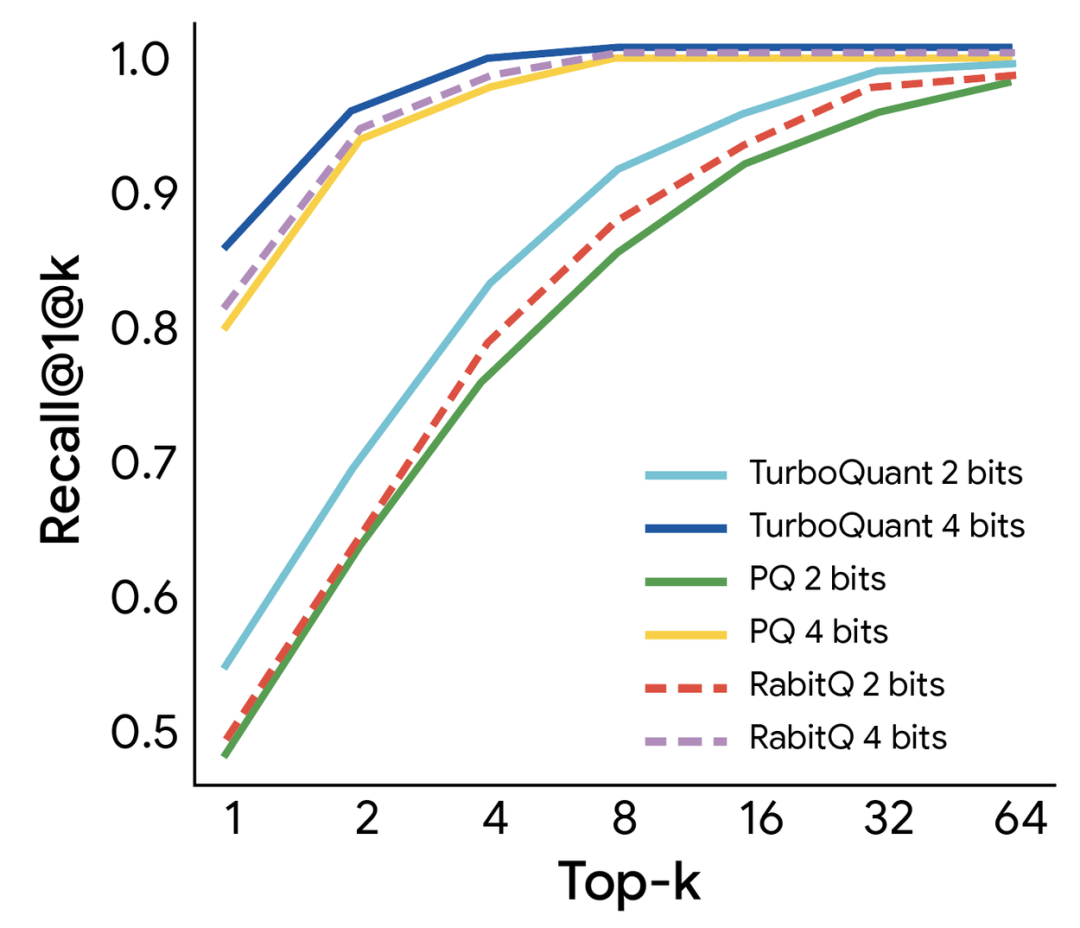
On high-dimensional data, TurboQuant also dominates. On the GloVe dataset with 200 dimensions, compared to previous methods like PQ and RabbiQ, TurboQuant achieves higher recall rates. These methods require complex training and parameter tuning. TurboQuant wins across the board.
The deeper meaning is that TurboQuant is not just a compression algorithm. It represents a fundamental shift in how we think about AI hardware. If memory requirements drop by 6 times, the entire supply chain changes. Data centers need fewer chips. Consumer devices can run larger models. The barrier to entry for AI inference collapses.
Within 24 hours of the paper’s release, Reddit users had already replicated the results. One developer implemented a custom Triton kernel in PyTorch and ran 2-bit quantized Gemma 3 4B on an RTX 4090. The output matched the uncompressed version exactly.

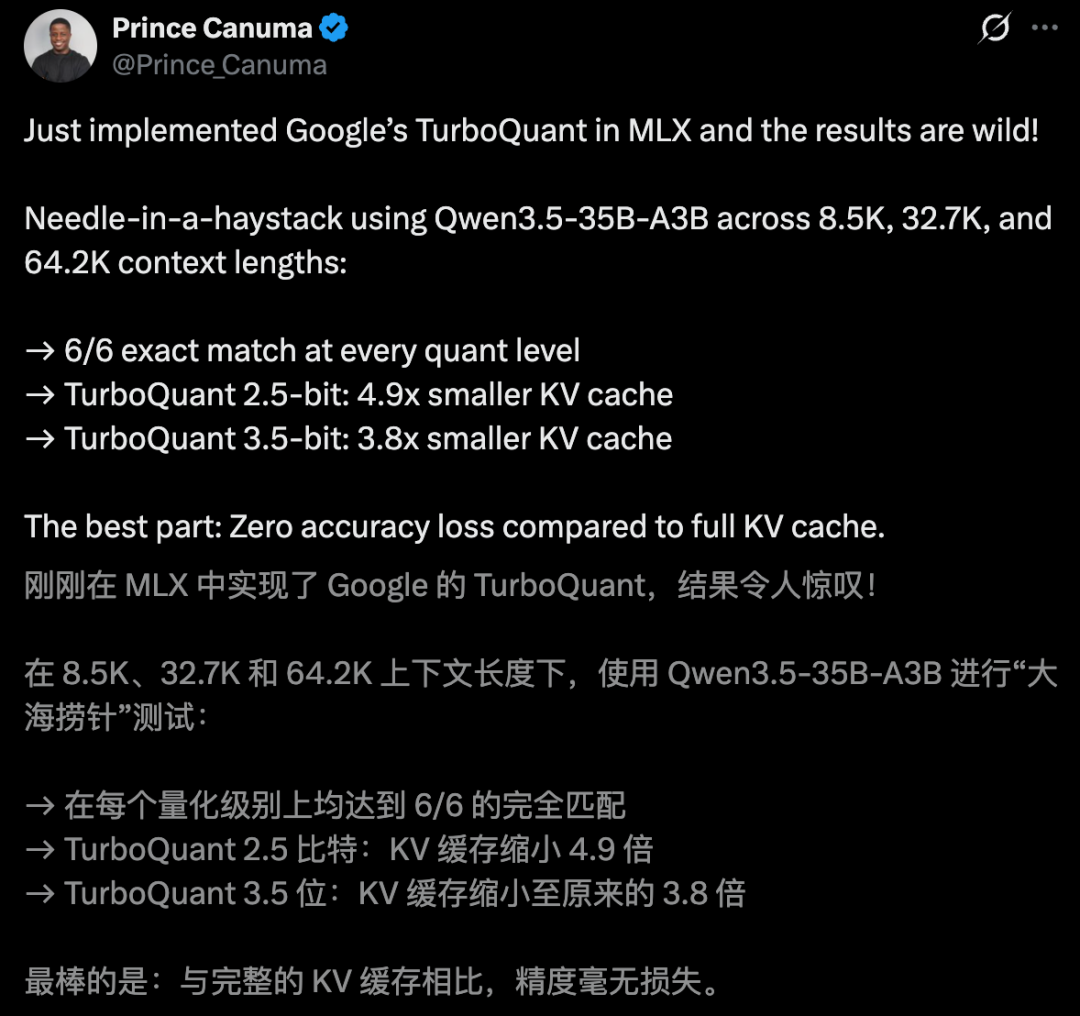
Another developer, Prince Canuma, tested TurboQuant on large models with 8.5 billion and 64.2 billion parameters. At 2.5-bit quantization, KV cache shrank by 4.9 times. At 3.5-bit, it still achieved 3.8 times reduction.
undress ai remover
For memory chip companies, the question is no longer whether demand will grow. It is whether the old assumptions about memory growth still hold. If AI models need 6 times less memory, the memory supercycle that investors bet on may never arrive.
The technology industry has a pattern. Every time efficiency improves, demand shifts. When Google made search faster, people searched more. When video compression improved, streaming replaced downloads. With TurboQuant, cheaper inference could mean more AI deployment, but on cheaper hardware.
The paper will be presented at ICLR 2026 and AISTATS 2026. By then, the industry will have absorbed the shock. Chip makers will adjust their roadmaps. Data center builders will recalculate their needs. And consumers will benefit from AI that runs faster, cheaper, and on smaller devices.
A 16GB Mac mini running a large model used to be a dream. With TurboQuant, it becomes reality. The future of AI is not just bigger models. It is smarter compression. Google just proved that the hardware race is not the only game in town.