OpenAI just dropped a double surprise. GPT-5.4 mini and GPT-5.4 nano are here. And they are about to change how every developer builds with AI.
No warning. No countdown. Just a quiet launch that is already shaking the industry.
Here is the big question. If a small AI model can handle real coding tasks, complex reasoning, and computer vision at nearly the same level as the full version, why would anyone pay three times more for the flagship?
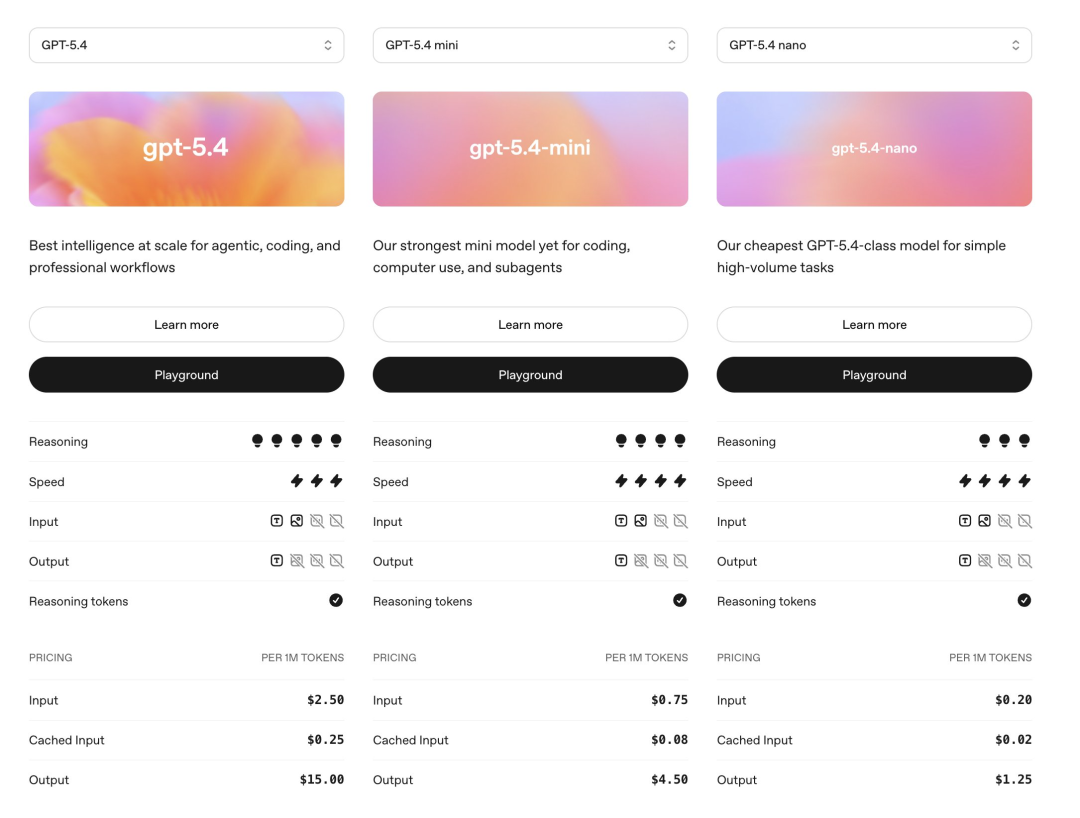
That is exactly what OpenAI is asking with this release. GPT-5.4 mini inherits the same architecture as the full GPT-5.4. It is faster. It is cheaper. And in many real-world tasks, it is almost indistinguishable from its bigger brother.
The numbers are shocking. Let us break them down.
The Price Drop That Changes Everything
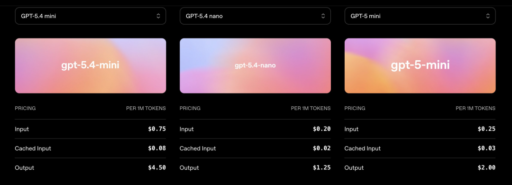
GPT-5.4 mini costs $0.75 per million input tokens and $4.50 per million output tokens. It supports a 400,000 token context window. That is massive for a small model.
GPT-5.4 nano costs just $0.20 per million input tokens and $1.25 per million output tokens. Yes, you read that right. Twenty cents.
Compared to the full GPT-5.4, mini is one-third the price. Nano is one-twelfth. And both are available to all developers right now through the API, Codex, and ChatGPT.
But price means nothing without performance. So let us look at the benchmarks.
Coding Benchmarks: Mini Nearly Matches the Full Model
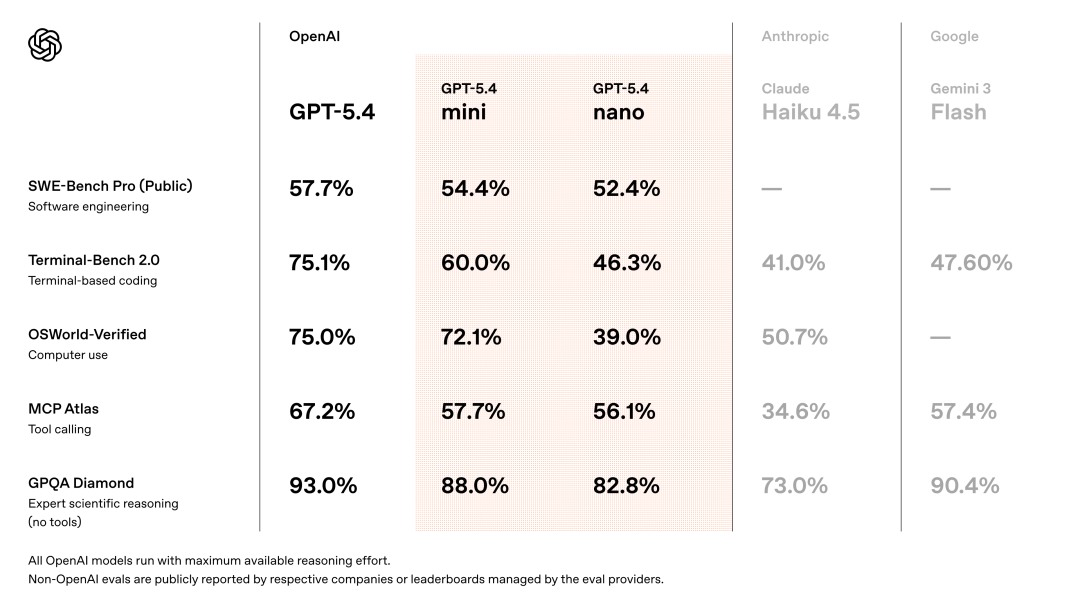
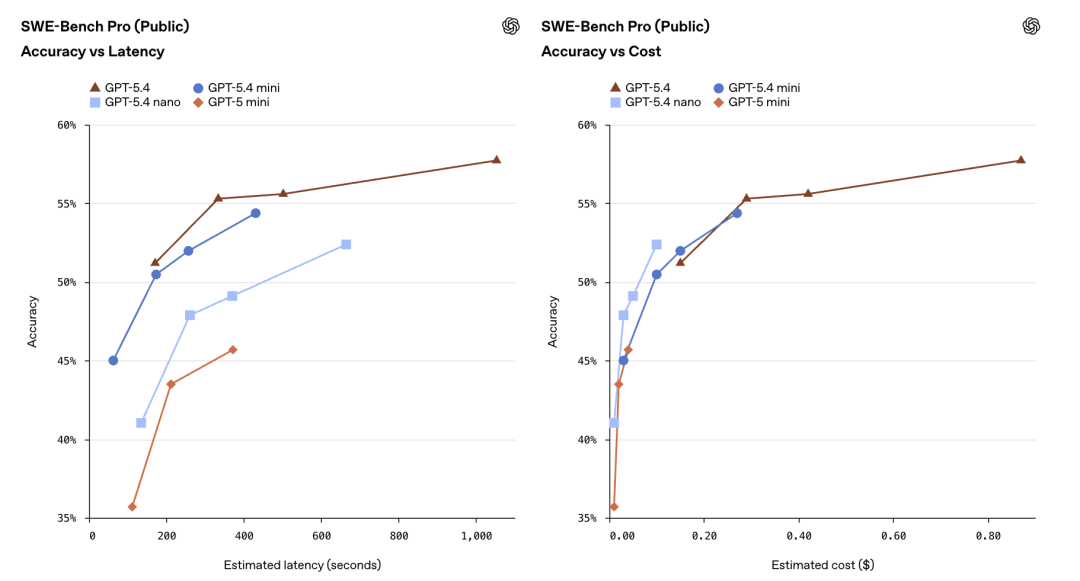
SWE-Bench Pro is the gold standard for real-world coding. It tests whether an AI can fix actual bugs on GitHub. GPT-5.4 mini scores 54.4%. The full GPT-5.4 scores 57.7%. That is only a 3.3% gap.
For context, the previous GPT-5 mini scored 45.7%. So the new mini improved by nearly 9 percentage points. That is not a small upgrade. That is a generational leap.
Ai clothing remover
On Terminal-Bench 2.0, which measures command-line tool use, GPT-5.4 mini hits 60.0%. The old GPT-5 mini only managed 38.2%. That is a 57% relative improvement.
Even the tiny nano model scores 52.4% on SWE-Bench Pro. That is just 7% behind mini. For a model that costs one-twelfth of the flagship price, this is unheard of.
cuckold chat
Reasoning and Tool Use: Mini Beats the Previous Generation
GPQA Diamond is a graduate-level science benchmark. GPT-5.4 mini scores 88%. That is just 5% behind the full model. For tasks that require deep scientific reasoning, mini is essentially a flagship model at a third of the cost.
Toolathlon tests how well an AI handles complex multi-step tool calls. This is not just about calling one API. It is about chaining multiple tools together, handling errors, and completing real workflows. GPT-5.4 mini scores 42.9%. The old GPT-5 mini only managed 26.9%. That is a crushing victory.
nude ai generator
On the industry-specific 2-bench standard, mini scores 93.4%. The full model scores 98.9%. The old GPT-5 mini only hit 74.1%. Again, mini is far closer to the flagship than to its predecessor.
On the MCP Atlas benchmark for tool use, GPT-5.4 mini scores 57.7% versus GPT-5 mini at 47.6%. These numbers tell one clear story. GPT-5.4 mini is not just a smaller model. It is a smarter model.

Computer Vision: Small Models See the World Too
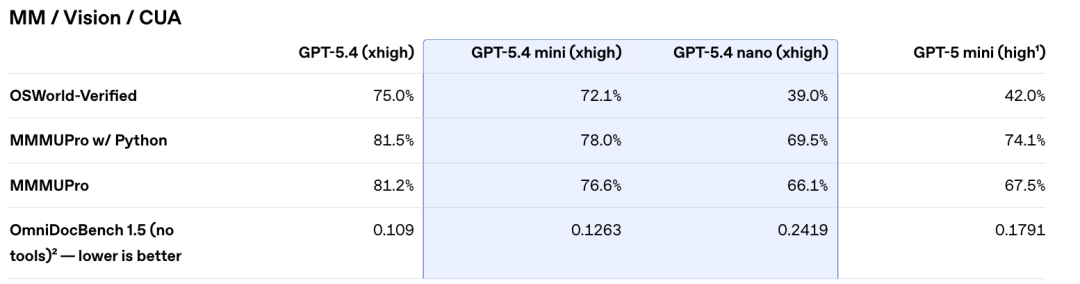
GPT-5.4 mini also shines in computer vision tasks. OSWorld-Verified is a comprehensive test that combines screen understanding, mouse control, and keyboard input. It simulates how a real user would interact with a computer interface.
GPT-5.4 mini scores 72.1%. The full GPT-5.4 scores 75.0%. The gap is under 3 percentage points. The old GPT-5 mini only managed 42.0%. That means the new mini is nearly twice as good at using a computer as its predecessor.
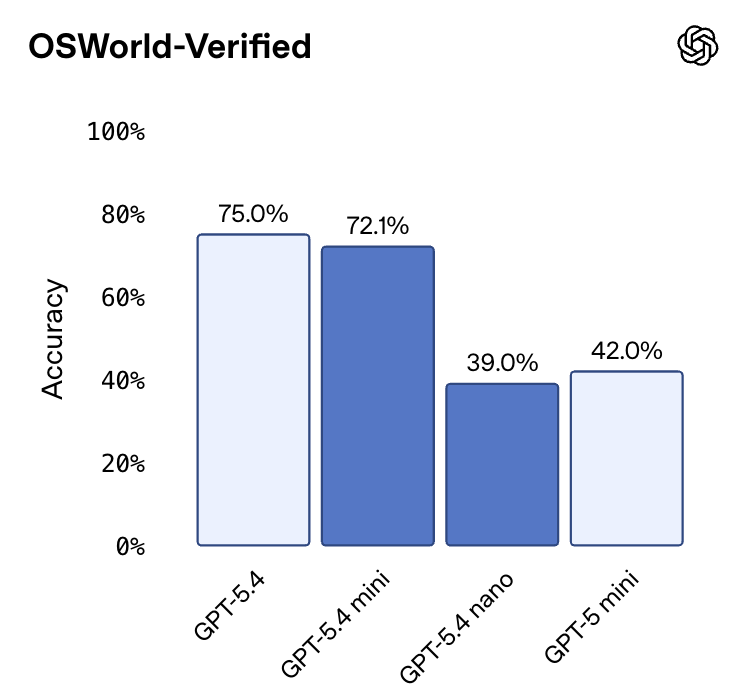
Even nano scores 39.0% on OSWorld. That is almost matching the old GPT-5 mini at 42.0%. For vision tasks that require high spatial reasoning, small models are no longer a joke.
On MMMU Pro, which combines images with math and coding problems, mini scores 78.0% versus the flagship at 81.5%. Again, the gap is tiny.
Why This Matters for AI Agents
Here is where things get exciting. These small models are not just benchmarks on a page. They are built for real AI agents.
A small model that can quickly process screen captures, identify UI elements, click buttons, and type text is exactly what an autonomous agent needs. It needs to observe the screen, plan the next step, and execute it in real time. Speed matters. Cost matters. And now, mini delivers both.
OpenAI also released a new version of Codex, their coding agent. The architecture is revealing. The flagship GPT-5.4 handles planning and strategy. Then it delegates the actual coding work to GPT-5.4 mini. The result is a system that thinks like a senior engineer but costs like a junior one.
The Multi-Model Future Is Here
OpenAI published a blog post alongside the release. The core idea is simple. The best AI systems do not rely on one big model. They use a mix of models, each doing what it does best.
The flagship GPT-5.4 plans the architecture and breaks down complex tasks. Then GPT-5.4 mini executes the bulk of the work. For simple tasks like formatting, summarizing, or basic file operations, even nano can handle them.

In the new Codex, this routing is already live. Users can see GPT-5.4 making the high-level plan, then mini taking over for the detailed implementation. Codex with mini costs only 30% of what Codex with the full model costs.
Same prediction quality. One-third the price. That is the power of model routing.
This is not a new idea in AI research. But OpenAI is the first to ship it at scale. The industry has talked about model cascades and routing for years. Now it is a product feature.
Hebbia CTO Aabhas Sharma put it well. GPT-5.4 mini achieves near-flagship performance on reasoning and coding at a fraction of the cost. It is not just a cheaper alternative. It enables higher throughput and more complex agent workflows that were previously too expensive to run.
Where to Use These Models
GPT-5.4 mini is available everywhere today. API. Codex. ChatGPT. All tiers.
The API pricing is $0.75 per million input tokens and $4.50 per million output tokens. Context window is 400,000 tokens. It supports text, images, audio, tool use, reasoning, and structured output. Basically everything the full model does.
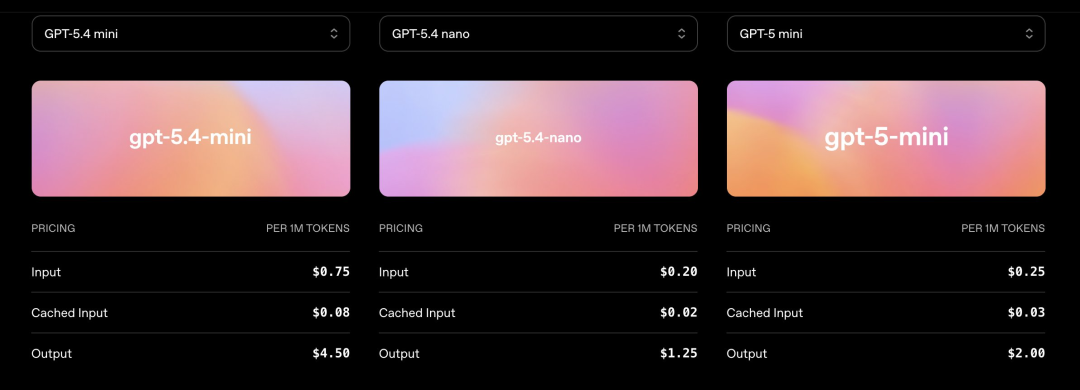
GPT-5.4 nano is also live on the API at $0.20 per million input tokens and $1.25 per million output tokens. That makes nano roughly one-fourth the price of mini for both input and output.
For classification, data extraction, and simple responses, nano offers unbeatable value.
In ChatGPT, GPT-5.4 mini is now the default for Plus and Pro users. The Thinking mode in the app now uses mini automatically when the full GPT-5.4 Thinking would be too slow. Most users will not even notice the switch. The experience feels the same. The cost is much lower.
Where Mini Falls Short
Let us be honest. Mini is not perfect.
On extremely long context tasks, the gap between mini and the flagship widens. On the OpenAI MRCR v2 benchmark with 64,000 to 128,000 token passages, GPT-5.4 scores 86.0% while mini only hits 47.7%. That is a 40-point gap. At 128,000 to 256,000 tokens, the scores are 79.3% versus 33.6%.
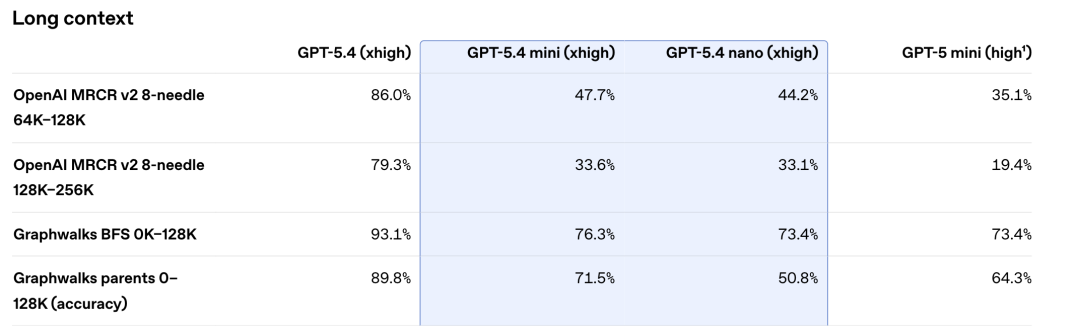
On the Graphwalks series, which tests multi-hop reasoning over long documents, GPT-5.4 scores 89.8% while mini manages 71.5%. When you need to track precise information across hundreds of pages and follow complex logical chains, the flagship still wins.
For tasks that require deep creativity, nuanced writing, or maintaining long-running conversations with full context awareness, GPT-5.4 remains the better choice. OpenAI is not hiding this. They are being transparent about the trade-offs.
The strategy is clear. Mini does not need to beat the flagship at everything. It just needs to beat it at speed, cost, and tool use. And it does.
The Community Reaction
The response has been overwhelming. On X, developers are sharing their first impressions.
One user wrote, I have been testing these models on real-world tasks and they are incredibly good. There are a few things that need work, but we are working on it. Thank you all for the feedback.
Another joked, This is basically a bomb.
Some users pointed out a deeper issue. One developer noted that model alignment and safety training might be pushing models toward overly cautious responses. They wrote, Models must not be trained to please these benchmark vendors. We need to push for more red teaming and safety research.
Others expressed gratitude. One user said, Thank you for the model. We are all waiting for the API.
There is also a fascinating philosophical debate happening. One user asked whether AI models are being trained to please benchmark creators rather than solve real problems. They compared it to how search engine optimization changed the web. When you optimize for a test, you sometimes lose sight of what actually matters.

It is a fair point. But the benchmarks here are not abstract puzzles. SWE-Bench Pro uses real GitHub bugs. OSWorld uses real computer interfaces. These are not tests you can game with clever prompting. They measure whether the model can actually do the work.
What This Means for the Future
GPT-5.4 mini is not an incremental update. It is a strategic shift.
For the past two years, the AI industry chased bigger models. More parameters. More training data. More compute. The assumption was that intelligence scales with size. OpenAI just proved that efficiency matters just as much.
A model that scores 94% of the flagship on coding, 96% on computer use, and 95% on scientific reasoning, at one-third the price, is not a compromise. It is a new category.
The multi-model architecture is the real innovation here. The flagship thinks. The small model executes. Nano handles the simple stuff. Together, they form a system that is faster, cheaper, and often better than any single model working alone.
This is how AI will be built from now on. Not one giant brain doing everything. But a team of specialized models, each playing its role, coordinated by a smart router.
For developers, this is great news. You no longer need to choose between quality and cost. You can have both. You can build agents that reason like GPT-5.4 and run like GPT-5.4 mini. You can process millions of tokens without breaking your budget.
For competitors, the pressure just increased. Google, Anthropic, and the open-source community now need to match not just OpenAI’s flagship, but their entire model family. The game has changed from who has the biggest model to who has the smartest system.
OpenAI did not just release two new models. They released a blueprint for the future of AI infrastructure.
Have you tried GPT-5.4 mini or nano? Share your results in the comments. And subscribe for weekly updates on AI model releases and developer tools.

